Species distribution models: Ecological explanation and prediction across space and time
2
2009
... 物种分布模型(Species Distribution Model,SDM)也称生态位模型(Ecological Niche Models,ENM),是一种基于物种存在或丰富度数据以及环境因子数据的数学模型[1],该类模型在环境因子组成的多维生态空间中,依据采样点提供的统计信息估计物种的生态位需求,然后投射到选定的时空范围内,以概率的形式反映物种对生境的偏好程度[2~7],模型结果通常反映大尺度上物种适宜生境分布.作为生物地理学研究的重要方法之一,物种分布模型的应用越来越广泛,近年来愈来愈多的此类研究关注于全球变化背景下生态系统的关键组分(建群种和常见物种等)对气候变化的响应[2,7],入侵物种的潜在分布区预测[8],区域气候变化对物种丰富度以及群落稳定性的影响[9,10],濒危珍稀物种保护区范围划定以及人类活动对濒危物种影响等方面[11,12]. ...
... 这里的外推性是指模型在空间、时间以及尺度上的外推性[1,2].空间上的外推最为典型的是外来物种入侵风险分析的相关研究,在此过程中,研究者应该避免选择物种原生产地与目标区域差异显著的间接变量,重点考虑气候土壤等直接变量因子.同时也不应该考虑原生产地生物相互作用等外源性因素,需要注意的是在入侵过程中,物种在目标区域可能会产生适宜性的生态位漂移[77].时间上的外推最为典型的是同一区域内气候变化对目标物种潜在分布区的影响,此类研究不应该仅考虑气候因子(气温和降水),还应该考虑物种扩散能力,以及环境中其他限制因子(土壤和植被)等,尤其是对于某些环境限制较强的特殊生境物种.物种分布模型空间尺度的转换较难实现,通常,在不同空间尺度上,物种的生态位显示不同的特征,其环境阈值也不同,需要其他信息辅助[4,78],尤其是针对物种分布模型的降尺度研究中. ...
A framework for using niche models to estimate impacts of climate change on species distributions
3
2013
... 物种分布模型(Species Distribution Model,SDM)也称生态位模型(Ecological Niche Models,ENM),是一种基于物种存在或丰富度数据以及环境因子数据的数学模型[1],该类模型在环境因子组成的多维生态空间中,依据采样点提供的统计信息估计物种的生态位需求,然后投射到选定的时空范围内,以概率的形式反映物种对生境的偏好程度[2~7],模型结果通常反映大尺度上物种适宜生境分布.作为生物地理学研究的重要方法之一,物种分布模型的应用越来越广泛,近年来愈来愈多的此类研究关注于全球变化背景下生态系统的关键组分(建群种和常见物种等)对气候变化的响应[2,7],入侵物种的潜在分布区预测[8],区域气候变化对物种丰富度以及群落稳定性的影响[9,10],濒危珍稀物种保护区范围划定以及人类活动对濒危物种影响等方面[11,12]. ...
... [2,7],入侵物种的潜在分布区预测[8],区域气候变化对物种丰富度以及群落稳定性的影响[9,10],濒危珍稀物种保护区范围划定以及人类活动对濒危物种影响等方面[11,12]. ...
... 这里的外推性是指模型在空间、时间以及尺度上的外推性[1,2].空间上的外推最为典型的是外来物种入侵风险分析的相关研究,在此过程中,研究者应该避免选择物种原生产地与目标区域差异显著的间接变量,重点考虑气候土壤等直接变量因子.同时也不应该考虑原生产地生物相互作用等外源性因素,需要注意的是在入侵过程中,物种在目标区域可能会产生适宜性的生态位漂移[77].时间上的外推最为典型的是同一区域内气候变化对目标物种潜在分布区的影响,此类研究不应该仅考虑气候因子(气温和降水),还应该考虑物种扩散能力,以及环境中其他限制因子(土壤和植被)等,尤其是对于某些环境限制较强的特殊生境物种.物种分布模型空间尺度的转换较难实现,通常,在不同空间尺度上,物种的生态位显示不同的特征,其环境阈值也不同,需要其他信息辅助[4,78],尤其是针对物种分布模型的降尺度研究中. ...
Performance tradeoffs in target-group bias correction for species distribution models
1
2017
... 目前,大多数物种分布模型在建模时不考虑生物相互作用,或者只在小尺度上考虑生物相互作用过程,因此模型通常只采用非生物的环境因子进行建模[3,4,6,94].然而已有研究证明将生物相互作用加入到模型中可以更好地模拟物种分布格局以及其对环境变化的响应[95,96].生物交互作用一般以如下方式集成到物种分布模型中:栅格单元内其他物种出现数据[96];目标物种所占比例数据[97];竞争系数[98];埃尔顿噪声假说(Eltonian noise hypothesis)[99]等.从理论上看,物种对于大的气候条件梯度的响应反映了哈钦森(Hutchinson)的多维超体积生态位.因此,物种分布模式在不同尺度下受到非生物预测因子和生物相互作用变量的影响,生物相互作用的重要性因尺度和位置而异[97].综上所述,未来物种分布模型研究应该将生物相互作用纳入模型框架内,同时在此过程中要着重考虑尺度效应对生物相互作用的影响. ...
10
2017
... 在过去的30年中,科学家们已经开发了许多模型来估计物种间关系和相关的环境变量.在建模过程中针对不同的建模目的、物种生态位特征以及建模数据基础,研究者需要选择不同模型算法.通常情况下模型算法越复杂其统计学精度也越高,但在某些情形下简单模型也有着不可替代的优势.如广义线性模型(Generalized Linear Model, GLM)是显式的,该算法可以给出解释变量的系数(包括它们的二次项和交互项),据此研究者可以直观的确定环境变量对物种分布的作用与重要性[16].相反,另外一些模型,如 混合判别式分析模型(Mixture Discriminant Analysis,MDA)、广义增强模型(Generalized Boosting Model,GBM)、分类与回归树(Classification and Regression Tree,CART)等由于其复杂性,很难进行有意义的生态解释.复杂的机器学习算法,如随机森林(Random Forest,RF)、支持向量机(Support Vector Machine,SVM)和人工神经网络(Artificial Neural Network,ANN)等黑箱模型,尽管易于使用,相对准确率高,但建模过程几乎不具备生态学意义.目前物种分布模型构建过程中模型的选择没有统一的解决方法,关于模型优劣的讨论屡见不鲜,例如:基于回归的算法与基于决策树的算法的比较[17],基于统计模型的算法与基于机器学习的算法的比较[18],参数化和非参数化模型的比较[5,19],以及物种采样点信息的需求方案(仅依靠存在点位建模以及存在点和非存在点数据集建模)的比较等[4].目前确定的结论包括:同一模型采取存在点和非存在点数据集的建模精度优于只依靠存在点数据的模型[4];在算法中加入增强(boosting)以及投票(bagging)机制进行优化的模型,如RF和推进式回归树(Boosted Regression Tree, BRT)等,与传统模型算法相比具有较好的模型精度[20,21]. ...
... [4];在算法中加入增强(boosting)以及投票(bagging)机制进行优化的模型,如RF和推进式回归树(Boosted Regression Tree, BRT)等,与传统模型算法相比具有较好的模型精度[20,21]. ...
... 本文将目前常用的模型算法归纳为8类(表1),并总结了不同类别模型算法的优缺点以及对采样点数据的需求,有助于研究者在相关研究时进行模型选择[4,6,8,16~21,26,27,31~45]. ...
... 在实际的物种分布建模过程中,一般根据一个或者多个模型精度统计学评价指标,在相同的建模数据基础上对模型结果进行检验,选择统计学上精度最高的算法[4,6,16,18,38].在进行多物种分布建模时,该方法可能导致不同的物种选择不同的模型,使得跨物种模型比较无法实现.同时在不同的建模条件下,通常只知道给定的数据集执行哪种模型最好,而在不同时空条件下,环境条件和预测之间的关系可能会改变,就无法使用同一模型.最优的模型算法不一定在所有建模条件下都能达到统计学精度最优,也不一定能有效地降低普遍存在的抽样偏差[46].因此为了减少模型的不确定性,增加模型的精度,近年来能够利用多个模型信息的集合模型(Ensemble model)预测成为物种分布研究的趋势[4,47].集合模型将主要趋势(即平均值、中位数或其他百分位数)和所有模型的总体变化(以及不确定性)映射起来,也可以集成不同模型的其他方面,如变量的重要性或模型响应曲线[4,48]. ...
... [4,47].集合模型将主要趋势(即平均值、中位数或其他百分位数)和所有模型的总体变化(以及不确定性)映射起来,也可以集成不同模型的其他方面,如变量的重要性或模型响应曲线[4,48]. ...
... [4,48]. ...
... (2)环境因子带来的不确定性.环境因子的共线性.研究表明目前物种分布模型常用的环境因子数据,如Worldclim数据[64]的部分环境因子存在较强的共线性,会造成建模时统计信息的冗余,同时也会对建模的结果产生不利的影响[65,66].在环境数据准备时采用主成分分析(Principal Component Analysis,PCA)、相关系数(r)或者方差膨胀因子(Variance Inflation Factor,VIF)来对环境因子进行降维处理,可以有效地解决这一问题[4,67].环境因子的空间分辨率.环境因子的空间分辨率决定了物种分布模型结果的空间分辨率,不同尺度的研究应使用不同大小的空间分辨率,对于全球范围内的研究,可以使用较小分辨率的数据(2.5~10 min)[68],但是在区域尺度上应该使用较大分辨率的数据(30 s甚至更细分辨率的数据)[69].一般而言数据栅格空间范围越大,检验点落在该栅格上的几率也就越大,模型精度也会越高.但是不应该为了追求模型的高准确性而损失细节,较大尺度的模型结果在区域范围内几乎没有指导物种人工种植和规划保护区的价值. ...
... 物种分布模型不仅适用于生态学基础性研究,也适用于应用性研究.如识别物种分布的主要影响因素[71],测试生物地理假说[72],评估生态位保守性[73],评估生物入侵风险[8],或评估全球变化对物种分布和多样性的影响等[74,75].同时此类模型也越来越多地应用于同物种不同特征表现的研究,如功能性状、次生类群或基因,在此基础上,与其他学科的工具和数据耦合,能够为谱系生物地理学、系统发育学、群体遗传学、种群动态等方面的研究提供便利[4,74,76].但是在具体实践研究时面临着以下挑战. ...
... 这里的外推性是指模型在空间、时间以及尺度上的外推性[1,2].空间上的外推最为典型的是外来物种入侵风险分析的相关研究,在此过程中,研究者应该避免选择物种原生产地与目标区域差异显著的间接变量,重点考虑气候土壤等直接变量因子.同时也不应该考虑原生产地生物相互作用等外源性因素,需要注意的是在入侵过程中,物种在目标区域可能会产生适宜性的生态位漂移[77].时间上的外推最为典型的是同一区域内气候变化对目标物种潜在分布区的影响,此类研究不应该仅考虑气候因子(气温和降水),还应该考虑物种扩散能力,以及环境中其他限制因子(土壤和植被)等,尤其是对于某些环境限制较强的特殊生境物种.物种分布模型空间尺度的转换较难实现,通常,在不同空间尺度上,物种的生态位显示不同的特征,其环境阈值也不同,需要其他信息辅助[4,78],尤其是针对物种分布模型的降尺度研究中. ...
... 目前,大多数物种分布模型在建模时不考虑生物相互作用,或者只在小尺度上考虑生物相互作用过程,因此模型通常只采用非生物的环境因子进行建模[3,4,6,94].然而已有研究证明将生物相互作用加入到模型中可以更好地模拟物种分布格局以及其对环境变化的响应[95,96].生物交互作用一般以如下方式集成到物种分布模型中:栅格单元内其他物种出现数据[96];目标物种所占比例数据[97];竞争系数[98];埃尔顿噪声假说(Eltonian noise hypothesis)[99]等.从理论上看,物种对于大的气候条件梯度的响应反映了哈钦森(Hutchinson)的多维超体积生态位.因此,物种分布模式在不同尺度下受到非生物预测因子和生物相互作用变量的影响,生物相互作用的重要性因尺度和位置而异[97].综上所述,未来物种分布模型研究应该将生物相互作用纳入模型框架内,同时在此过程中要着重考虑尺度效应对生物相互作用的影响. ...
生态位模型的理论基础、发展方向与挑战
1
2013
... 在过去的30年中,科学家们已经开发了许多模型来估计物种间关系和相关的环境变量.在建模过程中针对不同的建模目的、物种生态位特征以及建模数据基础,研究者需要选择不同模型算法.通常情况下模型算法越复杂其统计学精度也越高,但在某些情形下简单模型也有着不可替代的优势.如广义线性模型(Generalized Linear Model, GLM)是显式的,该算法可以给出解释变量的系数(包括它们的二次项和交互项),据此研究者可以直观的确定环境变量对物种分布的作用与重要性[16].相反,另外一些模型,如 混合判别式分析模型(Mixture Discriminant Analysis,MDA)、广义增强模型(Generalized Boosting Model,GBM)、分类与回归树(Classification and Regression Tree,CART)等由于其复杂性,很难进行有意义的生态解释.复杂的机器学习算法,如随机森林(Random Forest,RF)、支持向量机(Support Vector Machine,SVM)和人工神经网络(Artificial Neural Network,ANN)等黑箱模型,尽管易于使用,相对准确率高,但建模过程几乎不具备生态学意义.目前物种分布模型构建过程中模型的选择没有统一的解决方法,关于模型优劣的讨论屡见不鲜,例如:基于回归的算法与基于决策树的算法的比较[17],基于统计模型的算法与基于机器学习的算法的比较[18],参数化和非参数化模型的比较[5,19],以及物种采样点信息的需求方案(仅依靠存在点位建模以及存在点和非存在点数据集建模)的比较等[4].目前确定的结论包括:同一模型采取存在点和非存在点数据集的建模精度优于只依靠存在点数据的模型[4];在算法中加入增强(boosting)以及投票(bagging)机制进行优化的模型,如RF和推进式回归树(Boosted Regression Tree, BRT)等,与传统模型算法相比具有较好的模型精度[20,21]. ...
生态位模型的理论基础、发展方向与挑战
1
2013
... 在过去的30年中,科学家们已经开发了许多模型来估计物种间关系和相关的环境变量.在建模过程中针对不同的建模目的、物种生态位特征以及建模数据基础,研究者需要选择不同模型算法.通常情况下模型算法越复杂其统计学精度也越高,但在某些情形下简单模型也有着不可替代的优势.如广义线性模型(Generalized Linear Model, GLM)是显式的,该算法可以给出解释变量的系数(包括它们的二次项和交互项),据此研究者可以直观的确定环境变量对物种分布的作用与重要性[16].相反,另外一些模型,如 混合判别式分析模型(Mixture Discriminant Analysis,MDA)、广义增强模型(Generalized Boosting Model,GBM)、分类与回归树(Classification and Regression Tree,CART)等由于其复杂性,很难进行有意义的生态解释.复杂的机器学习算法,如随机森林(Random Forest,RF)、支持向量机(Support Vector Machine,SVM)和人工神经网络(Artificial Neural Network,ANN)等黑箱模型,尽管易于使用,相对准确率高,但建模过程几乎不具备生态学意义.目前物种分布模型构建过程中模型的选择没有统一的解决方法,关于模型优劣的讨论屡见不鲜,例如:基于回归的算法与基于决策树的算法的比较[17],基于统计模型的算法与基于机器学习的算法的比较[18],参数化和非参数化模型的比较[5,19],以及物种采样点信息的需求方案(仅依靠存在点位建模以及存在点和非存在点数据集建模)的比较等[4].目前确定的结论包括:同一模型采取存在点和非存在点数据集的建模精度优于只依靠存在点数据的模型[4];在算法中加入增强(boosting)以及投票(bagging)机制进行优化的模型,如RF和推进式回归树(Boosted Regression Tree, BRT)等,与传统模型算法相比具有较好的模型精度[20,21]. ...
物种分布模型的发展及评价方法
3
2015
... 本文将目前常用的模型算法归纳为8类(表1),并总结了不同类别模型算法的优缺点以及对采样点数据的需求,有助于研究者在相关研究时进行模型选择[4,6,8,16~21,26,27,31~45]. ...
... 在实际的物种分布建模过程中,一般根据一个或者多个模型精度统计学评价指标,在相同的建模数据基础上对模型结果进行检验,选择统计学上精度最高的算法[4,6,16,18,38].在进行多物种分布建模时,该方法可能导致不同的物种选择不同的模型,使得跨物种模型比较无法实现.同时在不同的建模条件下,通常只知道给定的数据集执行哪种模型最好,而在不同时空条件下,环境条件和预测之间的关系可能会改变,就无法使用同一模型.最优的模型算法不一定在所有建模条件下都能达到统计学精度最优,也不一定能有效地降低普遍存在的抽样偏差[46].因此为了减少模型的不确定性,增加模型的精度,近年来能够利用多个模型信息的集合模型(Ensemble model)预测成为物种分布研究的趋势[4,47].集合模型将主要趋势(即平均值、中位数或其他百分位数)和所有模型的总体变化(以及不确定性)映射起来,也可以集成不同模型的其他方面,如变量的重要性或模型响应曲线[4,48]. ...
... 目前,大多数物种分布模型在建模时不考虑生物相互作用,或者只在小尺度上考虑生物相互作用过程,因此模型通常只采用非生物的环境因子进行建模[3,4,6,94].然而已有研究证明将生物相互作用加入到模型中可以更好地模拟物种分布格局以及其对环境变化的响应[95,96].生物交互作用一般以如下方式集成到物种分布模型中:栅格单元内其他物种出现数据[96];目标物种所占比例数据[97];竞争系数[98];埃尔顿噪声假说(Eltonian noise hypothesis)[99]等.从理论上看,物种对于大的气候条件梯度的响应反映了哈钦森(Hutchinson)的多维超体积生态位.因此,物种分布模式在不同尺度下受到非生物预测因子和生物相互作用变量的影响,生物相互作用的重要性因尺度和位置而异[97].综上所述,未来物种分布模型研究应该将生物相互作用纳入模型框架内,同时在此过程中要着重考虑尺度效应对生物相互作用的影响. ...
物种分布模型的发展及评价方法
3
2015
... 本文将目前常用的模型算法归纳为8类(表1),并总结了不同类别模型算法的优缺点以及对采样点数据的需求,有助于研究者在相关研究时进行模型选择[4,6,8,16~21,26,27,31~45]. ...
... 在实际的物种分布建模过程中,一般根据一个或者多个模型精度统计学评价指标,在相同的建模数据基础上对模型结果进行检验,选择统计学上精度最高的算法[4,6,16,18,38].在进行多物种分布建模时,该方法可能导致不同的物种选择不同的模型,使得跨物种模型比较无法实现.同时在不同的建模条件下,通常只知道给定的数据集执行哪种模型最好,而在不同时空条件下,环境条件和预测之间的关系可能会改变,就无法使用同一模型.最优的模型算法不一定在所有建模条件下都能达到统计学精度最优,也不一定能有效地降低普遍存在的抽样偏差[46].因此为了减少模型的不确定性,增加模型的精度,近年来能够利用多个模型信息的集合模型(Ensemble model)预测成为物种分布研究的趋势[4,47].集合模型将主要趋势(即平均值、中位数或其他百分位数)和所有模型的总体变化(以及不确定性)映射起来,也可以集成不同模型的其他方面,如变量的重要性或模型响应曲线[4,48]. ...
... 目前,大多数物种分布模型在建模时不考虑生物相互作用,或者只在小尺度上考虑生物相互作用过程,因此模型通常只采用非生物的环境因子进行建模[3,4,6,94].然而已有研究证明将生物相互作用加入到模型中可以更好地模拟物种分布格局以及其对环境变化的响应[95,96].生物交互作用一般以如下方式集成到物种分布模型中:栅格单元内其他物种出现数据[96];目标物种所占比例数据[97];竞争系数[98];埃尔顿噪声假说(Eltonian noise hypothesis)[99]等.从理论上看,物种对于大的气候条件梯度的响应反映了哈钦森(Hutchinson)的多维超体积生态位.因此,物种分布模式在不同尺度下受到非生物预测因子和生物相互作用变量的影响,生物相互作用的重要性因尺度和位置而异[97].综上所述,未来物种分布模型研究应该将生物相互作用纳入模型框架内,同时在此过程中要着重考虑尺度效应对生物相互作用的影响. ...
How much does climate change threaten European forest tree species distributions?
2
2018
... 物种分布模型(Species Distribution Model,SDM)也称生态位模型(Ecological Niche Models,ENM),是一种基于物种存在或丰富度数据以及环境因子数据的数学模型[1],该类模型在环境因子组成的多维生态空间中,依据采样点提供的统计信息估计物种的生态位需求,然后投射到选定的时空范围内,以概率的形式反映物种对生境的偏好程度[2~7],模型结果通常反映大尺度上物种适宜生境分布.作为生物地理学研究的重要方法之一,物种分布模型的应用越来越广泛,近年来愈来愈多的此类研究关注于全球变化背景下生态系统的关键组分(建群种和常见物种等)对气候变化的响应[2,7],入侵物种的潜在分布区预测[8],区域气候变化对物种丰富度以及群落稳定性的影响[9,10],濒危珍稀物种保护区范围划定以及人类活动对濒危物种影响等方面[11,12]. ...
... ,7],入侵物种的潜在分布区预测[8],区域气候变化对物种丰富度以及群落稳定性的影响[9,10],濒危珍稀物种保护区范围划定以及人类活动对濒危物种影响等方面[11,12]. ...
Projecting future expansion of invasive species: Comparing and improving methodologies for species distribution modeling
3
2016
... 物种分布模型(Species Distribution Model,SDM)也称生态位模型(Ecological Niche Models,ENM),是一种基于物种存在或丰富度数据以及环境因子数据的数学模型[1],该类模型在环境因子组成的多维生态空间中,依据采样点提供的统计信息估计物种的生态位需求,然后投射到选定的时空范围内,以概率的形式反映物种对生境的偏好程度[2~7],模型结果通常反映大尺度上物种适宜生境分布.作为生物地理学研究的重要方法之一,物种分布模型的应用越来越广泛,近年来愈来愈多的此类研究关注于全球变化背景下生态系统的关键组分(建群种和常见物种等)对气候变化的响应[2,7],入侵物种的潜在分布区预测[8],区域气候变化对物种丰富度以及群落稳定性的影响[9,10],濒危珍稀物种保护区范围划定以及人类活动对濒危物种影响等方面[11,12]. ...
... 本文将目前常用的模型算法归纳为8类(表1),并总结了不同类别模型算法的优缺点以及对采样点数据的需求,有助于研究者在相关研究时进行模型选择[4,6,8,16~21,26,27,31~45]. ...
... 物种分布模型不仅适用于生态学基础性研究,也适用于应用性研究.如识别物种分布的主要影响因素[71],测试生物地理假说[72],评估生态位保守性[73],评估生物入侵风险[8],或评估全球变化对物种分布和多样性的影响等[74,75].同时此类模型也越来越多地应用于同物种不同特征表现的研究,如功能性状、次生类群或基因,在此基础上,与其他学科的工具和数据耦合,能够为谱系生物地理学、系统发育学、群体遗传学、种群动态等方面的研究提供便利[4,74,76].但是在具体实践研究时面临着以下挑战. ...
Using species distributions models for designing conservation strategies of Tropical Andean biodiversity under climate change
1
2014
... 物种分布模型(Species Distribution Model,SDM)也称生态位模型(Ecological Niche Models,ENM),是一种基于物种存在或丰富度数据以及环境因子数据的数学模型[1],该类模型在环境因子组成的多维生态空间中,依据采样点提供的统计信息估计物种的生态位需求,然后投射到选定的时空范围内,以概率的形式反映物种对生境的偏好程度[2~7],模型结果通常反映大尺度上物种适宜生境分布.作为生物地理学研究的重要方法之一,物种分布模型的应用越来越广泛,近年来愈来愈多的此类研究关注于全球变化背景下生态系统的关键组分(建群种和常见物种等)对气候变化的响应[2,7],入侵物种的潜在分布区预测[8],区域气候变化对物种丰富度以及群落稳定性的影响[9,10],濒危珍稀物种保护区范围划定以及人类活动对濒危物种影响等方面[11,12]. ...
SESAM—A new framework integrating macroecological and species distribution models for predicting spatio-temporal patterns of species assemblages
1
2011
... 物种分布模型(Species Distribution Model,SDM)也称生态位模型(Ecological Niche Models,ENM),是一种基于物种存在或丰富度数据以及环境因子数据的数学模型[1],该类模型在环境因子组成的多维生态空间中,依据采样点提供的统计信息估计物种的生态位需求,然后投射到选定的时空范围内,以概率的形式反映物种对生境的偏好程度[2~7],模型结果通常反映大尺度上物种适宜生境分布.作为生物地理学研究的重要方法之一,物种分布模型的应用越来越广泛,近年来愈来愈多的此类研究关注于全球变化背景下生态系统的关键组分(建群种和常见物种等)对气候变化的响应[2,7],入侵物种的潜在分布区预测[8],区域气候变化对物种丰富度以及群落稳定性的影响[9,10],濒危珍稀物种保护区范围划定以及人类活动对濒危物种影响等方面[11,12]. ...
Prediction of the potential geographic distribution of the ectomycorrhizal mushroom Tricholoma matsutake under multiple climate change scenarios
3
2017
... 物种分布模型(Species Distribution Model,SDM)也称生态位模型(Ecological Niche Models,ENM),是一种基于物种存在或丰富度数据以及环境因子数据的数学模型[1],该类模型在环境因子组成的多维生态空间中,依据采样点提供的统计信息估计物种的生态位需求,然后投射到选定的时空范围内,以概率的形式反映物种对生境的偏好程度[2~7],模型结果通常反映大尺度上物种适宜生境分布.作为生物地理学研究的重要方法之一,物种分布模型的应用越来越广泛,近年来愈来愈多的此类研究关注于全球变化背景下生态系统的关键组分(建群种和常见物种等)对气候变化的响应[2,7],入侵物种的潜在分布区预测[8],区域气候变化对物种丰富度以及群落稳定性的影响[9,10],濒危珍稀物种保护区范围划定以及人类活动对濒危物种影响等方面[11,12]. ...
... 这里适当的建模策略并不仅仅指选择合适的建模统计算法,更重要的是模型算法的组合策略.在某些特定的研究背景下,单一建模框架无法实现建模目标,就需要更为复杂的组合模型,如某些特殊生境物种(真菌蘑菇和荒漠植物等)对于环境中某些非气候环境因子依赖性较强,这些因子主导了此类物种的局地分布格局,同时也限制了物种在气候适宜生境中的扩散.为了解决这一问题,Guo 等[11,79]提出了综合物种分布模型构建策略,首先分别以气候因子等环境变量构建分布趋势模型,以限制环境因子构建物种分布限制模型,然后综合考虑两个模型的结果组成组合物种分布模型作为最终的模型结果,研究结果表明,该策略更加适合于特殊生境物种分布以及对其气候变化响应的研究.当物种分布模型建模目标不仅仅是物种适宜生境分布还包含物种其他定量评价目标时(生物量、种群适宜性和植物药材质量等),可以显示的表达环境因子与建模目标的统计关系的回归模型(广义线性、广义相加和模糊物元等)具有一定优势.同时在此类研究中,带额外信息的采样点数据一般较少,导致模型模拟的物种生态位边界过大或者过小,可以通过补充一般物种分布点位数据(存在—缺失数据)构建物种适宜生境分布模型,以此结果划定定量评价模型的研究范围. ...
... 国内的物种分布模型研究主要集中在对具体物种的潜在分布预测上,尤其是中文期刊文章,其主要研究对象为中草药[27,66]、经济作物[82]、荒漠物种[69,83]、濒危物种[11]以及外来入侵物种[68]等,研究目标主要集中于物种潜在适宜生境分布预测,气候变化背景下物种分布区的迁移以及灭绝风险,生物多样性评估,入侵风险评估等方面,主要研究方法是MAXENT等简单易用的模型软件(图3).其中中草药适宜生境以及其质量分布格局研究是我国物种分布研究的特色之一,研究者使用模糊数学方法,成功实现了在有限数据支持下,药材质量空间格局的预测与其对气候变化响应的相关研究[27,42,43]. ...
Species distribution models predict rare species occurrences despite significant effects of landscape context
1
2016
... 物种分布模型(Species Distribution Model,SDM)也称生态位模型(Ecological Niche Models,ENM),是一种基于物种存在或丰富度数据以及环境因子数据的数学模型[1],该类模型在环境因子组成的多维生态空间中,依据采样点提供的统计信息估计物种的生态位需求,然后投射到选定的时空范围内,以概率的形式反映物种对生境的偏好程度[2~7],模型结果通常反映大尺度上物种适宜生境分布.作为生物地理学研究的重要方法之一,物种分布模型的应用越来越广泛,近年来愈来愈多的此类研究关注于全球变化背景下生态系统的关键组分(建群种和常见物种等)对气候变化的响应[2,7],入侵物种的潜在分布区预测[8],区域气候变化对物种丰富度以及群落稳定性的影响[9,10],濒危珍稀物种保护区范围划定以及人类活动对濒危物种影响等方面[11,12]. ...
Predicting species distribution: Offering more than simple habitat models
1
2005
... 自20世纪70年代第一个真正意义上基于计算机技术的物种分布模型诞生以来[13,14],物种分布模型以及相关研究得到了长足发展,尤其是进入21世纪后,本领域的相关研究论文一直呈增长趋势(图1).但是目前部分相关研究只是利用界面友好,易于运行的物种分布模型软件平台进行简单的建模分析[15],模型选择缺乏依据,参数设置简单,模型结果不确定性较高;同时在分析过程中部分研究人员缺乏与模型构建有关的生态学过程、地理学背景以及统计学知识,导致其无法合理的解释模型结果,也无法进一步提高模型精度.作为一个新兴的研究领域,如何认识到当前存在的问题,摆脱发展面临的困境,是亟待解决的问题.本文从模型选择、参数设定和不确定性等几个方面深入剖析了该领域的发展现状,提出其发展所面临的挑战.同时也指出该领域可能的发展趋势,并结合中国的研究特点与优势,为我国学者开展相关研究提出建议. ...
Role of regression analysis in plant ecology
1
1971
... 自20世纪70年代第一个真正意义上基于计算机技术的物种分布模型诞生以来[13,14],物种分布模型以及相关研究得到了长足发展,尤其是进入21世纪后,本领域的相关研究论文一直呈增长趋势(图1).但是目前部分相关研究只是利用界面友好,易于运行的物种分布模型软件平台进行简单的建模分析[15],模型选择缺乏依据,参数设置简单,模型结果不确定性较高;同时在分析过程中部分研究人员缺乏与模型构建有关的生态学过程、地理学背景以及统计学知识,导致其无法合理的解释模型结果,也无法进一步提高模型精度.作为一个新兴的研究领域,如何认识到当前存在的问题,摆脱发展面临的困境,是亟待解决的问题.本文从模型选择、参数设定和不确定性等几个方面深入剖析了该领域的发展现状,提出其发展所面临的挑战.同时也指出该领域可能的发展趋势,并结合中国的研究特点与优势,为我国学者开展相关研究提出建议. ...
Computational science Troubling trends in scientific software use
1
2013
... 自20世纪70年代第一个真正意义上基于计算机技术的物种分布模型诞生以来[13,14],物种分布模型以及相关研究得到了长足发展,尤其是进入21世纪后,本领域的相关研究论文一直呈增长趋势(图1).但是目前部分相关研究只是利用界面友好,易于运行的物种分布模型软件平台进行简单的建模分析[15],模型选择缺乏依据,参数设置简单,模型结果不确定性较高;同时在分析过程中部分研究人员缺乏与模型构建有关的生态学过程、地理学背景以及统计学知识,导致其无法合理的解释模型结果,也无法进一步提高模型精度.作为一个新兴的研究领域,如何认识到当前存在的问题,摆脱发展面临的困境,是亟待解决的问题.本文从模型选择、参数设定和不确定性等几个方面深入剖析了该领域的发展现状,提出其发展所面临的挑战.同时也指出该领域可能的发展趋势,并结合中国的研究特点与优势,为我国学者开展相关研究提出建议. ...
Applying various algorithms for species distribution modelling
5
2013
... 在过去的30年中,科学家们已经开发了许多模型来估计物种间关系和相关的环境变量.在建模过程中针对不同的建模目的、物种生态位特征以及建模数据基础,研究者需要选择不同模型算法.通常情况下模型算法越复杂其统计学精度也越高,但在某些情形下简单模型也有着不可替代的优势.如广义线性模型(Generalized Linear Model, GLM)是显式的,该算法可以给出解释变量的系数(包括它们的二次项和交互项),据此研究者可以直观的确定环境变量对物种分布的作用与重要性[16].相反,另外一些模型,如 混合判别式分析模型(Mixture Discriminant Analysis,MDA)、广义增强模型(Generalized Boosting Model,GBM)、分类与回归树(Classification and Regression Tree,CART)等由于其复杂性,很难进行有意义的生态解释.复杂的机器学习算法,如随机森林(Random Forest,RF)、支持向量机(Support Vector Machine,SVM)和人工神经网络(Artificial Neural Network,ANN)等黑箱模型,尽管易于使用,相对准确率高,但建模过程几乎不具备生态学意义.目前物种分布模型构建过程中模型的选择没有统一的解决方法,关于模型优劣的讨论屡见不鲜,例如:基于回归的算法与基于决策树的算法的比较[17],基于统计模型的算法与基于机器学习的算法的比较[18],参数化和非参数化模型的比较[5,19],以及物种采样点信息的需求方案(仅依靠存在点位建模以及存在点和非存在点数据集建模)的比较等[4].目前确定的结论包括:同一模型采取存在点和非存在点数据集的建模精度优于只依靠存在点数据的模型[4];在算法中加入增强(boosting)以及投票(bagging)机制进行优化的模型,如RF和推进式回归树(Boosted Regression Tree, BRT)等,与传统模型算法相比具有较好的模型精度[20,21]. ...
... 本文将目前常用的模型算法归纳为8类(表1),并总结了不同类别模型算法的优缺点以及对采样点数据的需求,有助于研究者在相关研究时进行模型选择[4,6,8,16~21,26,27,31~45]. ...
... 柔性判别分析(Flexible Discriminant Analysis, FDA)[16,38] ...
... 推进式回归树(Boosted Regression Tree, BRT)[16,38] ...
... 在实际的物种分布建模过程中,一般根据一个或者多个模型精度统计学评价指标,在相同的建模数据基础上对模型结果进行检验,选择统计学上精度最高的算法[4,6,16,18,38].在进行多物种分布建模时,该方法可能导致不同的物种选择不同的模型,使得跨物种模型比较无法实现.同时在不同的建模条件下,通常只知道给定的数据集执行哪种模型最好,而在不同时空条件下,环境条件和预测之间的关系可能会改变,就无法使用同一模型.最优的模型算法不一定在所有建模条件下都能达到统计学精度最优,也不一定能有效地降低普遍存在的抽样偏差[46].因此为了减少模型的不确定性,增加模型的精度,近年来能够利用多个模型信息的集合模型(Ensemble model)预测成为物种分布研究的趋势[4,47].集合模型将主要趋势(即平均值、中位数或其他百分位数)和所有模型的总体变化(以及不确定性)映射起来,也可以集成不同模型的其他方面,如变量的重要性或模型响应曲线[4,48]. ...
Predicting species distributions: A critical comparison of the most common statistical models using artificial species
1
2010
... 在过去的30年中,科学家们已经开发了许多模型来估计物种间关系和相关的环境变量.在建模过程中针对不同的建模目的、物种生态位特征以及建模数据基础,研究者需要选择不同模型算法.通常情况下模型算法越复杂其统计学精度也越高,但在某些情形下简单模型也有着不可替代的优势.如广义线性模型(Generalized Linear Model, GLM)是显式的,该算法可以给出解释变量的系数(包括它们的二次项和交互项),据此研究者可以直观的确定环境变量对物种分布的作用与重要性[16].相反,另外一些模型,如 混合判别式分析模型(Mixture Discriminant Analysis,MDA)、广义增强模型(Generalized Boosting Model,GBM)、分类与回归树(Classification and Regression Tree,CART)等由于其复杂性,很难进行有意义的生态解释.复杂的机器学习算法,如随机森林(Random Forest,RF)、支持向量机(Support Vector Machine,SVM)和人工神经网络(Artificial Neural Network,ANN)等黑箱模型,尽管易于使用,相对准确率高,但建模过程几乎不具备生态学意义.目前物种分布模型构建过程中模型的选择没有统一的解决方法,关于模型优劣的讨论屡见不鲜,例如:基于回归的算法与基于决策树的算法的比较[17],基于统计模型的算法与基于机器学习的算法的比较[18],参数化和非参数化模型的比较[5,19],以及物种采样点信息的需求方案(仅依靠存在点位建模以及存在点和非存在点数据集建模)的比较等[4].目前确定的结论包括:同一模型采取存在点和非存在点数据集的建模精度优于只依靠存在点数据的模型[4];在算法中加入增强(boosting)以及投票(bagging)机制进行优化的模型,如RF和推进式回归树(Boosted Regression Tree, BRT)等,与传统模型算法相比具有较好的模型精度[20,21]. ...
An evaluation of methods for modelling species distributions
2
2004
... 在过去的30年中,科学家们已经开发了许多模型来估计物种间关系和相关的环境变量.在建模过程中针对不同的建模目的、物种生态位特征以及建模数据基础,研究者需要选择不同模型算法.通常情况下模型算法越复杂其统计学精度也越高,但在某些情形下简单模型也有着不可替代的优势.如广义线性模型(Generalized Linear Model, GLM)是显式的,该算法可以给出解释变量的系数(包括它们的二次项和交互项),据此研究者可以直观的确定环境变量对物种分布的作用与重要性[16].相反,另外一些模型,如 混合判别式分析模型(Mixture Discriminant Analysis,MDA)、广义增强模型(Generalized Boosting Model,GBM)、分类与回归树(Classification and Regression Tree,CART)等由于其复杂性,很难进行有意义的生态解释.复杂的机器学习算法,如随机森林(Random Forest,RF)、支持向量机(Support Vector Machine,SVM)和人工神经网络(Artificial Neural Network,ANN)等黑箱模型,尽管易于使用,相对准确率高,但建模过程几乎不具备生态学意义.目前物种分布模型构建过程中模型的选择没有统一的解决方法,关于模型优劣的讨论屡见不鲜,例如:基于回归的算法与基于决策树的算法的比较[17],基于统计模型的算法与基于机器学习的算法的比较[18],参数化和非参数化模型的比较[5,19],以及物种采样点信息的需求方案(仅依靠存在点位建模以及存在点和非存在点数据集建模)的比较等[4].目前确定的结论包括:同一模型采取存在点和非存在点数据集的建模精度优于只依靠存在点数据的模型[4];在算法中加入增强(boosting)以及投票(bagging)机制进行优化的模型,如RF和推进式回归树(Boosted Regression Tree, BRT)等,与传统模型算法相比具有较好的模型精度[20,21]. ...
... 在实际的物种分布建模过程中,一般根据一个或者多个模型精度统计学评价指标,在相同的建模数据基础上对模型结果进行检验,选择统计学上精度最高的算法[4,6,16,18,38].在进行多物种分布建模时,该方法可能导致不同的物种选择不同的模型,使得跨物种模型比较无法实现.同时在不同的建模条件下,通常只知道给定的数据集执行哪种模型最好,而在不同时空条件下,环境条件和预测之间的关系可能会改变,就无法使用同一模型.最优的模型算法不一定在所有建模条件下都能达到统计学精度最优,也不一定能有效地降低普遍存在的抽样偏差[46].因此为了减少模型的不确定性,增加模型的精度,近年来能够利用多个模型信息的集合模型(Ensemble model)预测成为物种分布研究的趋势[4,47].集合模型将主要趋势(即平均值、中位数或其他百分位数)和所有模型的总体变化(以及不确定性)映射起来,也可以集成不同模型的其他方面,如变量的重要性或模型响应曲线[4,48]. ...
Integrating occurrence data and expert maps for improved species range predictions
1
2016
... 在过去的30年中,科学家们已经开发了许多模型来估计物种间关系和相关的环境变量.在建模过程中针对不同的建模目的、物种生态位特征以及建模数据基础,研究者需要选择不同模型算法.通常情况下模型算法越复杂其统计学精度也越高,但在某些情形下简单模型也有着不可替代的优势.如广义线性模型(Generalized Linear Model, GLM)是显式的,该算法可以给出解释变量的系数(包括它们的二次项和交互项),据此研究者可以直观的确定环境变量对物种分布的作用与重要性[16].相反,另外一些模型,如 混合判别式分析模型(Mixture Discriminant Analysis,MDA)、广义增强模型(Generalized Boosting Model,GBM)、分类与回归树(Classification and Regression Tree,CART)等由于其复杂性,很难进行有意义的生态解释.复杂的机器学习算法,如随机森林(Random Forest,RF)、支持向量机(Support Vector Machine,SVM)和人工神经网络(Artificial Neural Network,ANN)等黑箱模型,尽管易于使用,相对准确率高,但建模过程几乎不具备生态学意义.目前物种分布模型构建过程中模型的选择没有统一的解决方法,关于模型优劣的讨论屡见不鲜,例如:基于回归的算法与基于决策树的算法的比较[17],基于统计模型的算法与基于机器学习的算法的比较[18],参数化和非参数化模型的比较[5,19],以及物种采样点信息的需求方案(仅依靠存在点位建模以及存在点和非存在点数据集建模)的比较等[4].目前确定的结论包括:同一模型采取存在点和非存在点数据集的建模精度优于只依靠存在点数据的模型[4];在算法中加入增强(boosting)以及投票(bagging)机制进行优化的模型,如RF和推进式回归树(Boosted Regression Tree, BRT)等,与传统模型算法相比具有较好的模型精度[20,21]. ...
Why choose Random Forest to predict rare species distribution with few samples in large undersampled areas?Three Asian crane species models provide supporting evidence
2
2017
... 在过去的30年中,科学家们已经开发了许多模型来估计物种间关系和相关的环境变量.在建模过程中针对不同的建模目的、物种生态位特征以及建模数据基础,研究者需要选择不同模型算法.通常情况下模型算法越复杂其统计学精度也越高,但在某些情形下简单模型也有着不可替代的优势.如广义线性模型(Generalized Linear Model, GLM)是显式的,该算法可以给出解释变量的系数(包括它们的二次项和交互项),据此研究者可以直观的确定环境变量对物种分布的作用与重要性[16].相反,另外一些模型,如 混合判别式分析模型(Mixture Discriminant Analysis,MDA)、广义增强模型(Generalized Boosting Model,GBM)、分类与回归树(Classification and Regression Tree,CART)等由于其复杂性,很难进行有意义的生态解释.复杂的机器学习算法,如随机森林(Random Forest,RF)、支持向量机(Support Vector Machine,SVM)和人工神经网络(Artificial Neural Network,ANN)等黑箱模型,尽管易于使用,相对准确率高,但建模过程几乎不具备生态学意义.目前物种分布模型构建过程中模型的选择没有统一的解决方法,关于模型优劣的讨论屡见不鲜,例如:基于回归的算法与基于决策树的算法的比较[17],基于统计模型的算法与基于机器学习的算法的比较[18],参数化和非参数化模型的比较[5,19],以及物种采样点信息的需求方案(仅依靠存在点位建模以及存在点和非存在点数据集建模)的比较等[4].目前确定的结论包括:同一模型采取存在点和非存在点数据集的建模精度优于只依靠存在点数据的模型[4];在算法中加入增强(boosting)以及投票(bagging)机制进行优化的模型,如RF和推进式回归树(Boosted Regression Tree, BRT)等,与传统模型算法相比具有较好的模型精度[20,21]. ...
... 随机森林(Random Forest, RF)[20]; ...
Novel methods improve prediction of species' distributions from occurrence data
2
2006
... 在过去的30年中,科学家们已经开发了许多模型来估计物种间关系和相关的环境变量.在建模过程中针对不同的建模目的、物种生态位特征以及建模数据基础,研究者需要选择不同模型算法.通常情况下模型算法越复杂其统计学精度也越高,但在某些情形下简单模型也有着不可替代的优势.如广义线性模型(Generalized Linear Model, GLM)是显式的,该算法可以给出解释变量的系数(包括它们的二次项和交互项),据此研究者可以直观的确定环境变量对物种分布的作用与重要性[16].相反,另外一些模型,如 混合判别式分析模型(Mixture Discriminant Analysis,MDA)、广义增强模型(Generalized Boosting Model,GBM)、分类与回归树(Classification and Regression Tree,CART)等由于其复杂性,很难进行有意义的生态解释.复杂的机器学习算法,如随机森林(Random Forest,RF)、支持向量机(Support Vector Machine,SVM)和人工神经网络(Artificial Neural Network,ANN)等黑箱模型,尽管易于使用,相对准确率高,但建模过程几乎不具备生态学意义.目前物种分布模型构建过程中模型的选择没有统一的解决方法,关于模型优劣的讨论屡见不鲜,例如:基于回归的算法与基于决策树的算法的比较[17],基于统计模型的算法与基于机器学习的算法的比较[18],参数化和非参数化模型的比较[5,19],以及物种采样点信息的需求方案(仅依靠存在点位建模以及存在点和非存在点数据集建模)的比较等[4].目前确定的结论包括:同一模型采取存在点和非存在点数据集的建模精度优于只依靠存在点数据的模型[4];在算法中加入增强(boosting)以及投票(bagging)机制进行优化的模型,如RF和推进式回归树(Boosted Regression Tree, BRT)等,与传统模型算法相比具有较好的模型精度[20,21]. ...
... 本文将目前常用的模型算法归纳为8类(表1),并总结了不同类别模型算法的优缺点以及对采样点数据的需求,有助于研究者在相关研究时进行模型选择[4,6,8,16~21,26,27,31~45]. ...
Selecting pseudo-absences for species distribution models: How, where and how many?
3
2012
... 在模型选择过程中,研究者还需要考虑采样点数据选择问题,不同的建模方法对于采样点的数据需求不同,除了物种分布(presences)数据外大部分模型还需要物种不分布(absences)数据,或者背景点(background)数据.这里首先需要说明的是3个概念:不分布数据,即真正意义上的物种无法分布的点位数据;伪不存在点(Pseudo-absences)表示物种不存在的点位,一般随机生成,所以不确定物种是否真的无法生存;背景点数据是研究区域内的所有点位或其随机样本,主要应用于Maxent和ENFA等模型中[22].在物种分布研究中,研究者一般是通过博物馆和标本馆的物种发生记录或者其他文献中的物种资源调查数据得到物种的分布数据,很难得到不分布数据,即需要在仅有分布数据(presence-only)的情形下建模[23~25],因此近十几年来物种分布模型发展的一个重要方向是解决presence-only建模问题.目前主要的解决方案有2种:(1)生成一定数量的伪不存在点,其生成方法包括从背景数据中随机生成;在与分布点的限定地理距离外生成;在与分布点环境不同的区域中生成[22].(2)使用仅利用分布数据即可建模的算法,如ENFA[26]、模糊数学[27]以及Kernel density estimation[28]等.但是在这个过程中确定生成的伪不存在点方法、伪不存在点的数量乃至伪不存在点的位置选择;处理存在点本身的空间趋势性(spatially biased)[29,30]以及其抽样策略、样本量造成的影响等都是物种分布模型面临的挑战. ...
... [22].(2)使用仅利用分布数据即可建模的算法,如ENFA[26]、模糊数学[27]以及Kernel density estimation[28]等.但是在这个过程中确定生成的伪不存在点方法、伪不存在点的数量乃至伪不存在点的位置选择;处理存在点本身的空间趋势性(spatially biased)[29,30]以及其抽样策略、样本量造成的影响等都是物种分布模型面临的挑战. ...
... (1)物种分布数据的不确定.物种采样点数据收集一般有实地调查、文献和标本馆记录等方法.物种采样点位置的不确定性必然会增加模型结果的不确定性.观测点坐标用于提取参与模型训练的环境变量值,因此位置误差可能导致物种—环境关系的不准确估计,这种影响的大小与环境变量的空间自相关程度有关.使用局部空间关联的方法可以识别那些导致模型精度显著降低的观测点位[60,61].此外标本库物种分布数据缺乏顶层设计,也往往无法覆盖所有物种存在的范围,属于不完全抽样,会导致生态位模拟的偏差[62,63],增加模型结果的不确定性.当然样本选择性偏差也是造成模型不确定的一个重要原因,这里的样本不仅仅包括物种分布数据的选择,也包括物种伪不存在点以及背景数据的选择[22,29,30]. ...
Likelihood analysis of species occurrence probability from presence-only data for modelling species distributions
1
2012
... 在模型选择过程中,研究者还需要考虑采样点数据选择问题,不同的建模方法对于采样点的数据需求不同,除了物种分布(presences)数据外大部分模型还需要物种不分布(absences)数据,或者背景点(background)数据.这里首先需要说明的是3个概念:不分布数据,即真正意义上的物种无法分布的点位数据;伪不存在点(Pseudo-absences)表示物种不存在的点位,一般随机生成,所以不确定物种是否真的无法生存;背景点数据是研究区域内的所有点位或其随机样本,主要应用于Maxent和ENFA等模型中[22].在物种分布研究中,研究者一般是通过博物馆和标本馆的物种发生记录或者其他文献中的物种资源调查数据得到物种的分布数据,很难得到不分布数据,即需要在仅有分布数据(presence-only)的情形下建模[23~25],因此近十几年来物种分布模型发展的一个重要方向是解决presence-only建模问题.目前主要的解决方案有2种:(1)生成一定数量的伪不存在点,其生成方法包括从背景数据中随机生成;在与分布点的限定地理距离外生成;在与分布点环境不同的区域中生成[22].(2)使用仅利用分布数据即可建模的算法,如ENFA[26]、模糊数学[27]以及Kernel density estimation[28]等.但是在这个过程中确定生成的伪不存在点方法、伪不存在点的数量乃至伪不存在点的位置选择;处理存在点本身的空间趋势性(spatially biased)[29,30]以及其抽样策略、样本量造成的影响等都是物种分布模型面临的挑战. ...
Presence-only data and the EM algorithm
2009
Evaluating presence-only species distribution models with discrimination accuracy is uninformative for many applications
1
2020
... 在模型选择过程中,研究者还需要考虑采样点数据选择问题,不同的建模方法对于采样点的数据需求不同,除了物种分布(presences)数据外大部分模型还需要物种不分布(absences)数据,或者背景点(background)数据.这里首先需要说明的是3个概念:不分布数据,即真正意义上的物种无法分布的点位数据;伪不存在点(Pseudo-absences)表示物种不存在的点位,一般随机生成,所以不确定物种是否真的无法生存;背景点数据是研究区域内的所有点位或其随机样本,主要应用于Maxent和ENFA等模型中[22].在物种分布研究中,研究者一般是通过博物馆和标本馆的物种发生记录或者其他文献中的物种资源调查数据得到物种的分布数据,很难得到不分布数据,即需要在仅有分布数据(presence-only)的情形下建模[23~25],因此近十几年来物种分布模型发展的一个重要方向是解决presence-only建模问题.目前主要的解决方案有2种:(1)生成一定数量的伪不存在点,其生成方法包括从背景数据中随机生成;在与分布点的限定地理距离外生成;在与分布点环境不同的区域中生成[22].(2)使用仅利用分布数据即可建模的算法,如ENFA[26]、模糊数学[27]以及Kernel density estimation[28]等.但是在这个过程中确定生成的伪不存在点方法、伪不存在点的数量乃至伪不存在点的位置选择;处理存在点本身的空间趋势性(spatially biased)[29,30]以及其抽样策略、样本量造成的影响等都是物种分布模型面临的挑战. ...
Ecological niche factor analysis: How to compute habitat-suitability maps without absence data?
3
2002
... 在模型选择过程中,研究者还需要考虑采样点数据选择问题,不同的建模方法对于采样点的数据需求不同,除了物种分布(presences)数据外大部分模型还需要物种不分布(absences)数据,或者背景点(background)数据.这里首先需要说明的是3个概念:不分布数据,即真正意义上的物种无法分布的点位数据;伪不存在点(Pseudo-absences)表示物种不存在的点位,一般随机生成,所以不确定物种是否真的无法生存;背景点数据是研究区域内的所有点位或其随机样本,主要应用于Maxent和ENFA等模型中[22].在物种分布研究中,研究者一般是通过博物馆和标本馆的物种发生记录或者其他文献中的物种资源调查数据得到物种的分布数据,很难得到不分布数据,即需要在仅有分布数据(presence-only)的情形下建模[23~25],因此近十几年来物种分布模型发展的一个重要方向是解决presence-only建模问题.目前主要的解决方案有2种:(1)生成一定数量的伪不存在点,其生成方法包括从背景数据中随机生成;在与分布点的限定地理距离外生成;在与分布点环境不同的区域中生成[22].(2)使用仅利用分布数据即可建模的算法,如ENFA[26]、模糊数学[27]以及Kernel density estimation[28]等.但是在这个过程中确定生成的伪不存在点方法、伪不存在点的数量乃至伪不存在点的位置选择;处理存在点本身的空间趋势性(spatially biased)[29,30]以及其抽样策略、样本量造成的影响等都是物种分布模型面临的挑战. ...
... 本文将目前常用的模型算法归纳为8类(表1),并总结了不同类别模型算法的优缺点以及对采样点数据的需求,有助于研究者在相关研究时进行模型选择[4,6,8,16~21,26,27,31~45]. ...
... 生态位因子分析模型(Ecological Niche Factor Analysis,ENFA)[26]; ...
基于模糊物元模型的桃儿七潜在地理分布研究
5
2015
... 在模型选择过程中,研究者还需要考虑采样点数据选择问题,不同的建模方法对于采样点的数据需求不同,除了物种分布(presences)数据外大部分模型还需要物种不分布(absences)数据,或者背景点(background)数据.这里首先需要说明的是3个概念:不分布数据,即真正意义上的物种无法分布的点位数据;伪不存在点(Pseudo-absences)表示物种不存在的点位,一般随机生成,所以不确定物种是否真的无法生存;背景点数据是研究区域内的所有点位或其随机样本,主要应用于Maxent和ENFA等模型中[22].在物种分布研究中,研究者一般是通过博物馆和标本馆的物种发生记录或者其他文献中的物种资源调查数据得到物种的分布数据,很难得到不分布数据,即需要在仅有分布数据(presence-only)的情形下建模[23~25],因此近十几年来物种分布模型发展的一个重要方向是解决presence-only建模问题.目前主要的解决方案有2种:(1)生成一定数量的伪不存在点,其生成方法包括从背景数据中随机生成;在与分布点的限定地理距离外生成;在与分布点环境不同的区域中生成[22].(2)使用仅利用分布数据即可建模的算法,如ENFA[26]、模糊数学[27]以及Kernel density estimation[28]等.但是在这个过程中确定生成的伪不存在点方法、伪不存在点的数量乃至伪不存在点的位置选择;处理存在点本身的空间趋势性(spatially biased)[29,30]以及其抽样策略、样本量造成的影响等都是物种分布模型面临的挑战. ...
... 本文将目前常用的模型算法归纳为8类(表1),并总结了不同类别模型算法的优缺点以及对采样点数据的需求,有助于研究者在相关研究时进行模型选择[4,6,8,16~21,26,27,31~45]. ...
... 模糊物元模型(Fuzzy Matter Element, FME)[27,42,43]; ...
... 国内的物种分布模型研究主要集中在对具体物种的潜在分布预测上,尤其是中文期刊文章,其主要研究对象为中草药[27,66]、经济作物[82]、荒漠物种[69,83]、濒危物种[11]以及外来入侵物种[68]等,研究目标主要集中于物种潜在适宜生境分布预测,气候变化背景下物种分布区的迁移以及灭绝风险,生物多样性评估,入侵风险评估等方面,主要研究方法是MAXENT等简单易用的模型软件(图3).其中中草药适宜生境以及其质量分布格局研究是我国物种分布研究的特色之一,研究者使用模糊数学方法,成功实现了在有限数据支持下,药材质量空间格局的预测与其对气候变化响应的相关研究[27,42,43]. ...
... [27,42,43]. ...
基于模糊物元模型的桃儿七潜在地理分布研究
5
2015
... 在模型选择过程中,研究者还需要考虑采样点数据选择问题,不同的建模方法对于采样点的数据需求不同,除了物种分布(presences)数据外大部分模型还需要物种不分布(absences)数据,或者背景点(background)数据.这里首先需要说明的是3个概念:不分布数据,即真正意义上的物种无法分布的点位数据;伪不存在点(Pseudo-absences)表示物种不存在的点位,一般随机生成,所以不确定物种是否真的无法生存;背景点数据是研究区域内的所有点位或其随机样本,主要应用于Maxent和ENFA等模型中[22].在物种分布研究中,研究者一般是通过博物馆和标本馆的物种发生记录或者其他文献中的物种资源调查数据得到物种的分布数据,很难得到不分布数据,即需要在仅有分布数据(presence-only)的情形下建模[23~25],因此近十几年来物种分布模型发展的一个重要方向是解决presence-only建模问题.目前主要的解决方案有2种:(1)生成一定数量的伪不存在点,其生成方法包括从背景数据中随机生成;在与分布点的限定地理距离外生成;在与分布点环境不同的区域中生成[22].(2)使用仅利用分布数据即可建模的算法,如ENFA[26]、模糊数学[27]以及Kernel density estimation[28]等.但是在这个过程中确定生成的伪不存在点方法、伪不存在点的数量乃至伪不存在点的位置选择;处理存在点本身的空间趋势性(spatially biased)[29,30]以及其抽样策略、样本量造成的影响等都是物种分布模型面临的挑战. ...
... 本文将目前常用的模型算法归纳为8类(表1),并总结了不同类别模型算法的优缺点以及对采样点数据的需求,有助于研究者在相关研究时进行模型选择[4,6,8,16~21,26,27,31~45]. ...
... 模糊物元模型(Fuzzy Matter Element, FME)[27,42,43]; ...
... 国内的物种分布模型研究主要集中在对具体物种的潜在分布预测上,尤其是中文期刊文章,其主要研究对象为中草药[27,66]、经济作物[82]、荒漠物种[69,83]、濒危物种[11]以及外来入侵物种[68]等,研究目标主要集中于物种潜在适宜生境分布预测,气候变化背景下物种分布区的迁移以及灭绝风险,生物多样性评估,入侵风险评估等方面,主要研究方法是MAXENT等简单易用的模型软件(图3).其中中草药适宜生境以及其质量分布格局研究是我国物种分布研究的特色之一,研究者使用模糊数学方法,成功实现了在有限数据支持下,药材质量空间格局的预测与其对气候变化响应的相关研究[27,42,43]. ...
... [27,42,43]. ...
Modelling species habitat suitability from presence-only data using kernel density estimation
1
2018
... 在模型选择过程中,研究者还需要考虑采样点数据选择问题,不同的建模方法对于采样点的数据需求不同,除了物种分布(presences)数据外大部分模型还需要物种不分布(absences)数据,或者背景点(background)数据.这里首先需要说明的是3个概念:不分布数据,即真正意义上的物种无法分布的点位数据;伪不存在点(Pseudo-absences)表示物种不存在的点位,一般随机生成,所以不确定物种是否真的无法生存;背景点数据是研究区域内的所有点位或其随机样本,主要应用于Maxent和ENFA等模型中[22].在物种分布研究中,研究者一般是通过博物馆和标本馆的物种发生记录或者其他文献中的物种资源调查数据得到物种的分布数据,很难得到不分布数据,即需要在仅有分布数据(presence-only)的情形下建模[23~25],因此近十几年来物种分布模型发展的一个重要方向是解决presence-only建模问题.目前主要的解决方案有2种:(1)生成一定数量的伪不存在点,其生成方法包括从背景数据中随机生成;在与分布点的限定地理距离外生成;在与分布点环境不同的区域中生成[22].(2)使用仅利用分布数据即可建模的算法,如ENFA[26]、模糊数学[27]以及Kernel density estimation[28]等.但是在这个过程中确定生成的伪不存在点方法、伪不存在点的数量乃至伪不存在点的位置选择;处理存在点本身的空间趋势性(spatially biased)[29,30]以及其抽样策略、样本量造成的影响等都是物种分布模型面临的挑战. ...
The effects of small sample size and sample bias on threshold selection and accuracy assessment of species distribution models
2
2012
... 在模型选择过程中,研究者还需要考虑采样点数据选择问题,不同的建模方法对于采样点的数据需求不同,除了物种分布(presences)数据外大部分模型还需要物种不分布(absences)数据,或者背景点(background)数据.这里首先需要说明的是3个概念:不分布数据,即真正意义上的物种无法分布的点位数据;伪不存在点(Pseudo-absences)表示物种不存在的点位,一般随机生成,所以不确定物种是否真的无法生存;背景点数据是研究区域内的所有点位或其随机样本,主要应用于Maxent和ENFA等模型中[22].在物种分布研究中,研究者一般是通过博物馆和标本馆的物种发生记录或者其他文献中的物种资源调查数据得到物种的分布数据,很难得到不分布数据,即需要在仅有分布数据(presence-only)的情形下建模[23~25],因此近十几年来物种分布模型发展的一个重要方向是解决presence-only建模问题.目前主要的解决方案有2种:(1)生成一定数量的伪不存在点,其生成方法包括从背景数据中随机生成;在与分布点的限定地理距离外生成;在与分布点环境不同的区域中生成[22].(2)使用仅利用分布数据即可建模的算法,如ENFA[26]、模糊数学[27]以及Kernel density estimation[28]等.但是在这个过程中确定生成的伪不存在点方法、伪不存在点的数量乃至伪不存在点的位置选择;处理存在点本身的空间趋势性(spatially biased)[29,30]以及其抽样策略、样本量造成的影响等都是物种分布模型面临的挑战. ...
... (1)物种分布数据的不确定.物种采样点数据收集一般有实地调查、文献和标本馆记录等方法.物种采样点位置的不确定性必然会增加模型结果的不确定性.观测点坐标用于提取参与模型训练的环境变量值,因此位置误差可能导致物种—环境关系的不准确估计,这种影响的大小与环境变量的空间自相关程度有关.使用局部空间关联的方法可以识别那些导致模型精度显著降低的观测点位[60,61].此外标本库物种分布数据缺乏顶层设计,也往往无法覆盖所有物种存在的范围,属于不完全抽样,会导致生态位模拟的偏差[62,63],增加模型结果的不确定性.当然样本选择性偏差也是造成模型不确定的一个重要原因,这里的样本不仅仅包括物种分布数据的选择,也包括物种伪不存在点以及背景数据的选择[22,29,30]. ...
Sampling bias in presence-only data used for species distribution modelling: Theory and methods for detecting sample bias and its effects on models
2
2018
... 在模型选择过程中,研究者还需要考虑采样点数据选择问题,不同的建模方法对于采样点的数据需求不同,除了物种分布(presences)数据外大部分模型还需要物种不分布(absences)数据,或者背景点(background)数据.这里首先需要说明的是3个概念:不分布数据,即真正意义上的物种无法分布的点位数据;伪不存在点(Pseudo-absences)表示物种不存在的点位,一般随机生成,所以不确定物种是否真的无法生存;背景点数据是研究区域内的所有点位或其随机样本,主要应用于Maxent和ENFA等模型中[22].在物种分布研究中,研究者一般是通过博物馆和标本馆的物种发生记录或者其他文献中的物种资源调查数据得到物种的分布数据,很难得到不分布数据,即需要在仅有分布数据(presence-only)的情形下建模[23~25],因此近十几年来物种分布模型发展的一个重要方向是解决presence-only建模问题.目前主要的解决方案有2种:(1)生成一定数量的伪不存在点,其生成方法包括从背景数据中随机生成;在与分布点的限定地理距离外生成;在与分布点环境不同的区域中生成[22].(2)使用仅利用分布数据即可建模的算法,如ENFA[26]、模糊数学[27]以及Kernel density estimation[28]等.但是在这个过程中确定生成的伪不存在点方法、伪不存在点的数量乃至伪不存在点的位置选择;处理存在点本身的空间趋势性(spatially biased)[29,30]以及其抽样策略、样本量造成的影响等都是物种分布模型面临的挑战. ...
... (1)物种分布数据的不确定.物种采样点数据收集一般有实地调查、文献和标本馆记录等方法.物种采样点位置的不确定性必然会增加模型结果的不确定性.观测点坐标用于提取参与模型训练的环境变量值,因此位置误差可能导致物种—环境关系的不准确估计,这种影响的大小与环境变量的空间自相关程度有关.使用局部空间关联的方法可以识别那些导致模型精度显著降低的观测点位[60,61].此外标本库物种分布数据缺乏顶层设计,也往往无法覆盖所有物种存在的范围,属于不完全抽样,会导致生态位模拟的偏差[62,63],增加模型结果的不确定性.当然样本选择性偏差也是造成模型不确定的一个重要原因,这里的样本不仅仅包括物种分布数据的选择,也包括物种伪不存在点以及背景数据的选择[22,29,30]. ...
BIOCLIM—A bioclimate analysis and prediction system
2
1991
... 本文将目前常用的模型算法归纳为8类(表1),并总结了不同类别模型算法的优缺点以及对采样点数据的需求,有助于研究者在相关研究时进行模型选择[4,6,8,16~21,26,27,31~45]. ...
... 表面分布区分室模型(Surface Range Envelope, SRE)[31]; ...
HABITAT: A procedure for modeling a disjoint environmental envelop for a plant or animal species
2
1991
... 栖息地模型(HABITAT)[32] ...
... 尽管物种分布模型在我国起步较晚,但经过相关领域研究学者的努力,近10年取得了迅速发展.综合中英文文献的调查结果,文章发表数目已经和国外同行无显著差别.在模型算法方面,我国学者首次将支持向量机[32]和DBSCAN[106]算法引入到物种分布模型,并提出了利用相关物种共同建模[107]和利用主成分分析进行多模型整合[108]等方法以提高模型整体准确率;出现了ModEco[109]、mMWeb[110]、NicheA[111]和SDMvspecies[112]等一系列的建模工具;另外,上文中提到的模型选择[54,113,114],参数设置[59],变量选择[115],模型的外推能力[116]等与模型构建和性能相关的研究领域,均有我国相关研究学者的成果发表. ...
DOMAIN: A flexible modelling procedure for mapping potential distributions of plants and animals
1
1993
... Gower距离(DOMAIN)[33]; ...
Assessment of alternative approaches for bioclimatic modeling with special emphasis on the Mahalanobis distance
2
2003
... 马氏距离(Mahalanobis Distance, MD)[34] ...
... 此外具体的物种保护或者生态系统管理工作一般都是区域尺度,需要十分精细的物种分布信息以及更加准确的区域基础信息.针对此种现状,在面向实践应用的相关研究中,较高分辨率且能够表现区域生境特征的环境变量更加适用,同时采用野外采样等方法获取更加精确的物种发生点位数据,也是保证模型在区域尺度精确性的主要手段之一[34,69],而在静态模型中结合土地利用变化等动态数据过滤物种分布模型结果,可以使物种分布模型的结果更加贴近实际,更加有指向性的为物种保护工作提出决策建议. ...
Generalized linear and generalized additive models in studies of species distributions: Setting the scene
2
2002
... 广义线性模型(Generalized Linear Model, GLM)[35]; ...
... 广义相加模型(Generalized Additive Model, GAM)[35]; ...
Predicting species distributions from museum and herbarium records using multiresponse models fitted with multivariate adaptive regression splines
1
2007
... 多元自回归样条模型(Multiple Adaptive Regression Splines, MARS)[36] ...
Effects of sample survey design on the accuracy of classification tree models in species distribution models
1
2006
... 分类树分析(Classification Tree Analysis, CTA)[37]; ...
The performance of state-of-the-art modelling techniques depends on geographical distribution of species
3
2009
... 柔性判别分析(Flexible Discriminant Analysis, FDA)[16,38] ...
... 推进式回归树(Boosted Regression Tree, BRT)[16,38] ...
... 在实际的物种分布建模过程中,一般根据一个或者多个模型精度统计学评价指标,在相同的建模数据基础上对模型结果进行检验,选择统计学上精度最高的算法[4,6,16,18,38].在进行多物种分布建模时,该方法可能导致不同的物种选择不同的模型,使得跨物种模型比较无法实现.同时在不同的建模条件下,通常只知道给定的数据集执行哪种模型最好,而在不同时空条件下,环境条件和预测之间的关系可能会改变,就无法使用同一模型.最优的模型算法不一定在所有建模条件下都能达到统计学精度最优,也不一定能有效地降低普遍存在的抽样偏差[46].因此为了减少模型的不确定性,增加模型的精度,近年来能够利用多个模型信息的集合模型(Ensemble model)预测成为物种分布研究的趋势[4,47].集合模型将主要趋势(即平均值、中位数或其他百分位数)和所有模型的总体变化(以及不确定性)映射起来,也可以集成不同模型的其他方面,如变量的重要性或模型响应曲线[4,48]. ...
Using artificial neural networks to map the spatial distribution of understorey bamboo from remote sensing data
2
2004
... 人工神经网络 (Artificial Neural Network, ANN)[39]; ...
... (3)模型算法的不确定性.物种分布模型中模型的选择和参数的设定都会带来建模结果的不确定性[39,49,70],因此根据建模目标的生理生态特征与建模数据的特征,选择合适的统计算法以及参数化方案显得尤为重要. ...
Support vector machines for predicting distribution of Sudden Oak Death in California
1
2005
... 支持向量机(Support Vector Machine, SVM)[40]; ...
Maximum entropy modeling of species geographic distributions
1
2006
... 推进式回归树(Boosted Regression Tree, BRT)
[16,38]物种分布数据;物种分布与不分布数据 | 精度较高;模拟结果比较收敛,提供了生境分布的细节,具有较好的空间表现 | 模型精度需要大数据量保证;可移植性差;不能提供清晰的统计学原理;存在过拟合等风险;计算成本高 | | 最大熵 | MaxEnt[41] | 物种分布—背景数据(最大熵模型);物种分布与不分布数据(判别最大熵) | 预测结果精度较高;在样本量相对较小的情况下能够取得较好的建模效果;模型可以仅依靠物种存在点数据建模;在统一建模框架下可以处理连续环境变量与分类环境变量;MaxEnt软件是免费的并且有友好的用户界面 | 由于其模型界面良好的封装性,无法调整相应程序;模型的时空外推能力仅在低阈值情况下较好;在较小的样本量情况下得出的结论可能对物种生态位模拟不完整,造成模拟结果失真;友好的模型界面也会造成模型的滥用 |
| 模糊数学 | 模糊物元模型(Fuzzy Matter Element, FME)[27,42,43]; ...
Assessing habitat suitability based on Geographic Information System (GIS) and fuzzy: A case study of Schisandra sphenanthera Rehd. et Wils. in Qinling Mountains, China
2
2012
... 模糊物元模型(Fuzzy Matter Element, FME)[27,42,43]; ...
... 国内的物种分布模型研究主要集中在对具体物种的潜在分布预测上,尤其是中文期刊文章,其主要研究对象为中草药[27,66]、经济作物[82]、荒漠物种[69,83]、濒危物种[11]以及外来入侵物种[68]等,研究目标主要集中于物种潜在适宜生境分布预测,气候变化背景下物种分布区的迁移以及灭绝风险,生物多样性评估,入侵风险评估等方面,主要研究方法是MAXENT等简单易用的模型软件(图3).其中中草药适宜生境以及其质量分布格局研究是我国物种分布研究的特色之一,研究者使用模糊数学方法,成功实现了在有限数据支持下,药材质量空间格局的预测与其对气候变化响应的相关研究[27,42,43]. ...
Predictions of the potential geographical distribution and quality of gynostemma pentaphyllum base on the fuzzy matter element model in China
2
2017
... 模糊物元模型(Fuzzy Matter Element, FME)[27,42,43]; ...
... 国内的物种分布模型研究主要集中在对具体物种的潜在分布预测上,尤其是中文期刊文章,其主要研究对象为中草药[27,66]、经济作物[82]、荒漠物种[69,83]、濒危物种[11]以及外来入侵物种[68]等,研究目标主要集中于物种潜在适宜生境分布预测,气候变化背景下物种分布区的迁移以及灭绝风险,生物多样性评估,入侵风险评估等方面,主要研究方法是MAXENT等简单易用的模型软件(图3).其中中草药适宜生境以及其质量分布格局研究是我国物种分布研究的特色之一,研究者使用模糊数学方法,成功实现了在有限数据支持下,药材质量空间格局的预测与其对气候变化响应的相关研究[27,42,43]. ...
Assessing the applicability of fuzzy neural networks for habitat preference evaluation of Japanese medaka (Oryzias latipes)
1
2011
... 模糊神经网络(Fuzzy Neural Networks, FNN)[44] ...
Bayesian networks for habitat suitability modeling: A potential tool for conservation planning with scarce resources
2
2014
... 本文将目前常用的模型算法归纳为8类(表1),并总结了不同类别模型算法的优缺点以及对采样点数据的需求,有助于研究者在相关研究时进行模型选择[4,6,8,16~21,26,27,31~45]. ...
... 目标物种成分含量数据 | 专家经验与实际采样点统计信息融入到隶属函数中,以实现有限采样点基础上的物种分布模型建模;针对复杂系统建模具有较高预测能力;可以有效地在空间上预测物种的某种特性(生物量,有效成分含量)的分布 | 针对不同的建模目标需要额外的采样点数据信息(生物量和有效成分含量等);完全由专家经验确定的隶属函数具有主观性 |
| 贝叶斯 网络 | 贝叶斯网络模型(Bayesian networks, BN)[45] | 物种分布数据 | 采用变量之间的概率关系的图形模型来构建模型;概率关系可以由统计数据得到也可以由专家经验生成;可以有效地整合专家知识;利用有限采样点数据构建稳健(robust)模型;建模过程有严格的生态学意义 | 以有向无循环图(Directed Acyclic Graph,DAG)相关节点(变量)之间的概率关系,在缺乏足够的专家知识或实验数据时,模型的构建存在随机性以及不确定性;只使用离散变量,会导致信息损失 |
在实际的物种分布建模过程中,一般根据一个或者多个模型精度统计学评价指标,在相同的建模数据基础上对模型结果进行检验,选择统计学上精度最高的算法[4,6,16,18,38].在进行多物种分布建模时,该方法可能导致不同的物种选择不同的模型,使得跨物种模型比较无法实现.同时在不同的建模条件下,通常只知道给定的数据集执行哪种模型最好,而在不同时空条件下,环境条件和预测之间的关系可能会改变,就无法使用同一模型.最优的模型算法不一定在所有建模条件下都能达到统计学精度最优,也不一定能有效地降低普遍存在的抽样偏差[46].因此为了减少模型的不确定性,增加模型的精度,近年来能够利用多个模型信息的集合模型(Ensemble model)预测成为物种分布研究的趋势[4,47].集合模型将主要趋势(即平均值、中位数或其他百分位数)和所有模型的总体变化(以及不确定性)映射起来,也可以集成不同模型的其他方面,如变量的重要性或模型响应曲线[4,48]. ...
Are niche- based species distribution models transferable in space?
1
2010
... 在实际的物种分布建模过程中,一般根据一个或者多个模型精度统计学评价指标,在相同的建模数据基础上对模型结果进行检验,选择统计学上精度最高的算法[4,6,16,18,38].在进行多物种分布建模时,该方法可能导致不同的物种选择不同的模型,使得跨物种模型比较无法实现.同时在不同的建模条件下,通常只知道给定的数据集执行哪种模型最好,而在不同时空条件下,环境条件和预测之间的关系可能会改变,就无法使用同一模型.最优的模型算法不一定在所有建模条件下都能达到统计学精度最优,也不一定能有效地降低普遍存在的抽样偏差[46].因此为了减少模型的不确定性,增加模型的精度,近年来能够利用多个模型信息的集合模型(Ensemble model)预测成为物种分布研究的趋势[4,47].集合模型将主要趋势(即平均值、中位数或其他百分位数)和所有模型的总体变化(以及不确定性)映射起来,也可以集成不同模型的其他方面,如变量的重要性或模型响应曲线[4,48]. ...
Ensemble modelling of species distribution: The effects of geographical and environmental ranges
2
2011
... 在实际的物种分布建模过程中,一般根据一个或者多个模型精度统计学评价指标,在相同的建模数据基础上对模型结果进行检验,选择统计学上精度最高的算法[4,6,16,18,38].在进行多物种分布建模时,该方法可能导致不同的物种选择不同的模型,使得跨物种模型比较无法实现.同时在不同的建模条件下,通常只知道给定的数据集执行哪种模型最好,而在不同时空条件下,环境条件和预测之间的关系可能会改变,就无法使用同一模型.最优的模型算法不一定在所有建模条件下都能达到统计学精度最优,也不一定能有效地降低普遍存在的抽样偏差[46].因此为了减少模型的不确定性,增加模型的精度,近年来能够利用多个模型信息的集合模型(Ensemble model)预测成为物种分布研究的趋势[4,47].集合模型将主要趋势(即平均值、中位数或其他百分位数)和所有模型的总体变化(以及不确定性)映射起来,也可以集成不同模型的其他方面,如变量的重要性或模型响应曲线[4,48]. ...
... 物种分布模型的结果一般要从连续的模型结果转化为存在和不存在的二分类结果,因此选择合适的分类阈值是模型构建中的重要步骤.阈值的选择一般有以下几种方法:依照生态学原理或者专家经验定义阈值,一般是0.5;使与阈值相关的评估方法得到模型评价结果最优的阈值,如Kappa系数最大化和TSS值最大化等方法;ROC曲线计算概率阈值,方法包括选择特异性等于敏感性的阈值,最大化特异性和敏感性之和,或选择ROC曲线上最接近(0,1)的点对应的概率;最低存在阈值,即计算一定比率(一般是95%)物种发生点位在模型结果中的概率值,以其最低概率为分类阈值[47,59].同样,没有任何一种阈值确定方式适合所有的建模场景,尤其是在建模数据本身存在偏差的情形中,阈值的选择应该更多的考虑物种本身的生态位特征以及研究的目的. ...
Uncertainty in ensemble forecasting of species distribution
1
2010
... 在实际的物种分布建模过程中,一般根据一个或者多个模型精度统计学评价指标,在相同的建模数据基础上对模型结果进行检验,选择统计学上精度最高的算法[4,6,16,18,38].在进行多物种分布建模时,该方法可能导致不同的物种选择不同的模型,使得跨物种模型比较无法实现.同时在不同的建模条件下,通常只知道给定的数据集执行哪种模型最好,而在不同时空条件下,环境条件和预测之间的关系可能会改变,就无法使用同一模型.最优的模型算法不一定在所有建模条件下都能达到统计学精度最优,也不一定能有效地降低普遍存在的抽样偏差[46].因此为了减少模型的不确定性,增加模型的精度,近年来能够利用多个模型信息的集合模型(Ensemble model)预测成为物种分布研究的趋势[4,47].集合模型将主要趋势(即平均值、中位数或其他百分位数)和所有模型的总体变化(以及不确定性)映射起来,也可以集成不同模型的其他方面,如变量的重要性或模型响应曲线[4,48]. ...
Measuring the relative effect of factors affecting species distribution model predictions
2
2014
... 模型参数是建模的重要环节之一,影响到除Bioclim和DOMAIN等以外的大部分物种分布模型的结果[49].实际上,建模的大部分工作就是在进行参数调优.就目前来看,大部分物种分布模型的参数调优工作还没有成熟的方法可以使用,更多的是依赖经验来进行[50].尽管ENMEval[51]、NicheA[52]和dismo[53]等工具包提供了相关的工具进行参数的批量调优功能,但是必须注意,任何的调参手段都无法确保得到全局最优解,而只能是局部最优解[54]. ...
... (3)模型算法的不确定性.物种分布模型中模型的选择和参数的设定都会带来建模结果的不确定性[39,49,70],因此根据建模目标的生理生态特征与建模数据的特征,选择合适的统计算法以及参数化方案显得尤为重要. ...
Species-specific tuning increases robustness to sampling bias in models of species distributions: An implementation with Maxent
1
2011
... 模型参数是建模的重要环节之一,影响到除Bioclim和DOMAIN等以外的大部分物种分布模型的结果[49].实际上,建模的大部分工作就是在进行参数调优.就目前来看,大部分物种分布模型的参数调优工作还没有成熟的方法可以使用,更多的是依赖经验来进行[50].尽管ENMEval[51]、NicheA[52]和dismo[53]等工具包提供了相关的工具进行参数的批量调优功能,但是必须注意,任何的调参手段都无法确保得到全局最优解,而只能是局部最优解[54]. ...
ENM eval: An R package for conducting spatially independent evaluations and estimating optimal model complexity for Maxent ecological niche models
1
2014
... 模型参数是建模的重要环节之一,影响到除Bioclim和DOMAIN等以外的大部分物种分布模型的结果[49].实际上,建模的大部分工作就是在进行参数调优.就目前来看,大部分物种分布模型的参数调优工作还没有成熟的方法可以使用,更多的是依赖经验来进行[50].尽管ENMEval[51]、NicheA[52]和dismo[53]等工具包提供了相关的工具进行参数的批量调优功能,但是必须注意,任何的调参手段都无法确保得到全局最优解,而只能是局部最优解[54]. ...
NicheA: Creating virtual species and ecological niches in multivariate environmental scenarios
1
2016
... 模型参数是建模的重要环节之一,影响到除Bioclim和DOMAIN等以外的大部分物种分布模型的结果[49].实际上,建模的大部分工作就是在进行参数调优.就目前来看,大部分物种分布模型的参数调优工作还没有成熟的方法可以使用,更多的是依赖经验来进行[50].尽管ENMEval[51]、NicheA[52]和dismo[53]等工具包提供了相关的工具进行参数的批量调优功能,但是必须注意,任何的调参手段都无法确保得到全局最优解,而只能是局部最优解[54]. ...
Dismo: Species Distribution Modeling
1
2016
... 模型参数是建模的重要环节之一,影响到除Bioclim和DOMAIN等以外的大部分物种分布模型的结果[49].实际上,建模的大部分工作就是在进行参数调优.就目前来看,大部分物种分布模型的参数调优工作还没有成熟的方法可以使用,更多的是依赖经验来进行[50].尽管ENMEval[51]、NicheA[52]和dismo[53]等工具包提供了相关的工具进行参数的批量调优功能,但是必须注意,任何的调参手段都无法确保得到全局最优解,而只能是局部最优解[54]. ...
No silver bullets in correlative ecological niche modelling: Insights from testing among many potential algorithms for niche estimation
2
2015
... 模型参数是建模的重要环节之一,影响到除Bioclim和DOMAIN等以外的大部分物种分布模型的结果[49].实际上,建模的大部分工作就是在进行参数调优.就目前来看,大部分物种分布模型的参数调优工作还没有成熟的方法可以使用,更多的是依赖经验来进行[50].尽管ENMEval[51]、NicheA[52]和dismo[53]等工具包提供了相关的工具进行参数的批量调优功能,但是必须注意,任何的调参手段都无法确保得到全局最优解,而只能是局部最优解[54]. ...
... 尽管物种分布模型在我国起步较晚,但经过相关领域研究学者的努力,近10年取得了迅速发展.综合中英文文献的调查结果,文章发表数目已经和国外同行无显著差别.在模型算法方面,我国学者首次将支持向量机[32]和DBSCAN[106]算法引入到物种分布模型,并提出了利用相关物种共同建模[107]和利用主成分分析进行多模型整合[108]等方法以提高模型整体准确率;出现了ModEco[109]、mMWeb[110]、NicheA[111]和SDMvspecies[112]等一系列的建模工具;另外,上文中提到的模型选择[54,113,114],参数设置[59],变量选择[115],模型的外推能力[116]等与模型构建和性能相关的研究领域,均有我国相关研究学者的成果发表. ...
Measuring and comparing the accuracy of species distribution models with presence-absence data
1
2011
... 参数效果需要合理的评估方法来支持,常用的模型评估方法包括Kappa系数、真实技巧统计值(True Skill Statistic,TSS)、受试者操作特征曲线下面积(Area Under Curve,AUC)、F分数(F-Score)以及分布数据校准曲线(POC plot)等[55,56],其中AUC通过计算一个数值便能提供模型在所有可能阈值范围上的性能评价结果,因此应用较为广泛,但是也有研究认为,AUC有其自身的缺陷,该方法实质上是指模型正确分类高于错误分类的概率,无法提供关于模型误差空间分布等信息,并不适用于所有的物种分布研究[57].而POC plot则在仅有分布数据(presence-only)的情形下即可校正模型,有助于模型校准的可视化探索,并可用于重新校准模拟精度较低的模型[56].但是POC plot并不能完全替代AUC等模型评估方法,不同的模型评估方法只能用于评价模型某些方面的性能,并没有通用的模型评估办法[58]. ...
POC plots: Calibrating species distribution models with presence-only data
2
2010
... 参数效果需要合理的评估方法来支持,常用的模型评估方法包括Kappa系数、真实技巧统计值(True Skill Statistic,TSS)、受试者操作特征曲线下面积(Area Under Curve,AUC)、F分数(F-Score)以及分布数据校准曲线(POC plot)等[55,56],其中AUC通过计算一个数值便能提供模型在所有可能阈值范围上的性能评价结果,因此应用较为广泛,但是也有研究认为,AUC有其自身的缺陷,该方法实质上是指模型正确分类高于错误分类的概率,无法提供关于模型误差空间分布等信息,并不适用于所有的物种分布研究[57].而POC plot则在仅有分布数据(presence-only)的情形下即可校正模型,有助于模型校准的可视化探索,并可用于重新校准模拟精度较低的模型[56].但是POC plot并不能完全替代AUC等模型评估方法,不同的模型评估方法只能用于评价模型某些方面的性能,并没有通用的模型评估办法[58]. ...
... [56].但是POC plot并不能完全替代AUC等模型评估方法,不同的模型评估方法只能用于评价模型某些方面的性能,并没有通用的模型评估办法[58]. ...
AUC: A misleading measure of the performance of predictive distribution models
1
2008
... 参数效果需要合理的评估方法来支持,常用的模型评估方法包括Kappa系数、真实技巧统计值(True Skill Statistic,TSS)、受试者操作特征曲线下面积(Area Under Curve,AUC)、F分数(F-Score)以及分布数据校准曲线(POC plot)等[55,56],其中AUC通过计算一个数值便能提供模型在所有可能阈值范围上的性能评价结果,因此应用较为广泛,但是也有研究认为,AUC有其自身的缺陷,该方法实质上是指模型正确分类高于错误分类的概率,无法提供关于模型误差空间分布等信息,并不适用于所有的物种分布研究[57].而POC plot则在仅有分布数据(presence-only)的情形下即可校正模型,有助于模型校准的可视化探索,并可用于重新校准模拟精度较低的模型[56].但是POC plot并不能完全替代AUC等模型评估方法,不同的模型评估方法只能用于评价模型某些方面的性能,并没有通用的模型评估办法[58]. ...
Is my species distribution model fit for purpose? Matching data and models to applications
1
2015
... 参数效果需要合理的评估方法来支持,常用的模型评估方法包括Kappa系数、真实技巧统计值(True Skill Statistic,TSS)、受试者操作特征曲线下面积(Area Under Curve,AUC)、F分数(F-Score)以及分布数据校准曲线(POC plot)等[55,56],其中AUC通过计算一个数值便能提供模型在所有可能阈值范围上的性能评价结果,因此应用较为广泛,但是也有研究认为,AUC有其自身的缺陷,该方法实质上是指模型正确分类高于错误分类的概率,无法提供关于模型误差空间分布等信息,并不适用于所有的物种分布研究[57].而POC plot则在仅有分布数据(presence-only)的情形下即可校正模型,有助于模型校准的可视化探索,并可用于重新校准模拟精度较低的模型[56].但是POC plot并不能完全替代AUC等模型评估方法,不同的模型评估方法只能用于评价模型某些方面的性能,并没有通用的模型评估办法[58]. ...
On the selection of thresholds for predicting species occurrence with presence-only data
3
2016
... 物种分布模型的结果一般要从连续的模型结果转化为存在和不存在的二分类结果,因此选择合适的分类阈值是模型构建中的重要步骤.阈值的选择一般有以下几种方法:依照生态学原理或者专家经验定义阈值,一般是0.5;使与阈值相关的评估方法得到模型评价结果最优的阈值,如Kappa系数最大化和TSS值最大化等方法;ROC曲线计算概率阈值,方法包括选择特异性等于敏感性的阈值,最大化特异性和敏感性之和,或选择ROC曲线上最接近(0,1)的点对应的概率;最低存在阈值,即计算一定比率(一般是95%)物种发生点位在模型结果中的概率值,以其最低概率为分类阈值[47,59].同样,没有任何一种阈值确定方式适合所有的建模场景,尤其是在建模数据本身存在偏差的情形中,阈值的选择应该更多的考虑物种本身的生态位特征以及研究的目的. ...
... 尽管物种分布模型在我国起步较晚,但经过相关领域研究学者的努力,近10年取得了迅速发展.综合中英文文献的调查结果,文章发表数目已经和国外同行无显著差别.在模型算法方面,我国学者首次将支持向量机[32]和DBSCAN[106]算法引入到物种分布模型,并提出了利用相关物种共同建模[107]和利用主成分分析进行多模型整合[108]等方法以提高模型整体准确率;出现了ModEco[109]、mMWeb[110]、NicheA[111]和SDMvspecies[112]等一系列的建模工具;另外,上文中提到的模型选择[54,113,114],参数设置[59],变量选择[115],模型的外推能力[116]等与模型构建和性能相关的研究领域,均有我国相关研究学者的成果发表. ...
... 最近几十年,地理学、统计学和计算机科学等相关学科和技术的发展极大地促进了物种分布模型的发展.但是在模型应用过程中,研究者往往对所研究的生态问题缺乏清楚的认识与表达,对模型算法和参数并不了解,仅仅通过文献模仿前人的工作,且没有针对性的筛选建模数据与模型算法,导致不确定性较大且难以解释的模型结果[59].本文系统总结了物种分布模型构建过程,回顾了模型的理论基础,着重指明了建模过程中的统计学规范,归纳总结了不同模型算法的优缺点及其应用情景,进一步论述了模型应用方面应注意的问题以及其发展趋势.此外,在物种分布模型建模实践中,模型结果的合理性和精确性受相关预测因子和建模方法的选择、时空尺度、环境和地理因素之间的相互作用以及模型外推程度的影响,因此研究者应理解模型的理论基础,重视模型的统计学规范,合理的选择模型算法,在未来的研究中应注重探讨造成物种当前分布格局的历史地理原因以及物种生态位演化造成的可能影响.在建模过程中结合谱系生物地理学和景观遗传学原理并将物种相关作用等生态过程有效地纳入到模型框架中,同时有效利用地学海量数据(如遥感数据)提高模型精度. ...
Spatial autocorrelation in predictors reduces the impact of positional uncertainty in occurrence data on species distribution modelling
1
2011
... (1)物种分布数据的不确定.物种采样点数据收集一般有实地调查、文献和标本馆记录等方法.物种采样点位置的不确定性必然会增加模型结果的不确定性.观测点坐标用于提取参与模型训练的环境变量值,因此位置误差可能导致物种—环境关系的不准确估计,这种影响的大小与环境变量的空间自相关程度有关.使用局部空间关联的方法可以识别那些导致模型精度显著降低的观测点位[60,61].此外标本库物种分布数据缺乏顶层设计,也往往无法覆盖所有物种存在的范围,属于不完全抽样,会导致生态位模拟的偏差[62,63],增加模型结果的不确定性.当然样本选择性偏差也是造成模型不确定的一个重要原因,这里的样本不仅仅包括物种分布数据的选择,也包括物种伪不存在点以及背景数据的选择[22,29,30]. ...
Where is positional uncertainty a problem for species distribution modelling?
1
2014
... (1)物种分布数据的不确定.物种采样点数据收集一般有实地调查、文献和标本馆记录等方法.物种采样点位置的不确定性必然会增加模型结果的不确定性.观测点坐标用于提取参与模型训练的环境变量值,因此位置误差可能导致物种—环境关系的不准确估计,这种影响的大小与环境变量的空间自相关程度有关.使用局部空间关联的方法可以识别那些导致模型精度显著降低的观测点位[60,61].此外标本库物种分布数据缺乏顶层设计,也往往无法覆盖所有物种存在的范围,属于不完全抽样,会导致生态位模拟的偏差[62,63],增加模型结果的不确定性.当然样本选择性偏差也是造成模型不确定的一个重要原因,这里的样本不仅仅包括物种分布数据的选择,也包括物种伪不存在点以及背景数据的选择[22,29,30]. ...
Sampling in ecology and evolution-bridging the gap between theory and practice
1
2011
... (1)物种分布数据的不确定.物种采样点数据收集一般有实地调查、文献和标本馆记录等方法.物种采样点位置的不确定性必然会增加模型结果的不确定性.观测点坐标用于提取参与模型训练的环境变量值,因此位置误差可能导致物种—环境关系的不准确估计,这种影响的大小与环境变量的空间自相关程度有关.使用局部空间关联的方法可以识别那些导致模型精度显著降低的观测点位[60,61].此外标本库物种分布数据缺乏顶层设计,也往往无法覆盖所有物种存在的范围,属于不完全抽样,会导致生态位模拟的偏差[62,63],增加模型结果的不确定性.当然样本选择性偏差也是造成模型不确定的一个重要原因,这里的样本不仅仅包括物种分布数据的选择,也包括物种伪不存在点以及背景数据的选择[22,29,30]. ...
Quality of presence data determines species distribution model performance: A novel index to evaluate data quality
1
2015
... (1)物种分布数据的不确定.物种采样点数据收集一般有实地调查、文献和标本馆记录等方法.物种采样点位置的不确定性必然会增加模型结果的不确定性.观测点坐标用于提取参与模型训练的环境变量值,因此位置误差可能导致物种—环境关系的不准确估计,这种影响的大小与环境变量的空间自相关程度有关.使用局部空间关联的方法可以识别那些导致模型精度显著降低的观测点位[60,61].此外标本库物种分布数据缺乏顶层设计,也往往无法覆盖所有物种存在的范围,属于不完全抽样,会导致生态位模拟的偏差[62,63],增加模型结果的不确定性.当然样本选择性偏差也是造成模型不确定的一个重要原因,这里的样本不仅仅包括物种分布数据的选择,也包括物种伪不存在点以及背景数据的选择[22,29,30]. ...
Worldclim 2: New 1-km spatial resolution climate surfaces for global land areas
1
2017
... (2)环境因子带来的不确定性.环境因子的共线性.研究表明目前物种分布模型常用的环境因子数据,如Worldclim数据[64]的部分环境因子存在较强的共线性,会造成建模时统计信息的冗余,同时也会对建模的结果产生不利的影响[65,66].在环境数据准备时采用主成分分析(Principal Component Analysis,PCA)、相关系数(r)或者方差膨胀因子(Variance Inflation Factor,VIF)来对环境因子进行降维处理,可以有效地解决这一问题[4,67].环境因子的空间分辨率.环境因子的空间分辨率决定了物种分布模型结果的空间分辨率,不同尺度的研究应使用不同大小的空间分辨率,对于全球范围内的研究,可以使用较小分辨率的数据(2.5~10 min)[68],但是在区域尺度上应该使用较大分辨率的数据(30 s甚至更细分辨率的数据)[69].一般而言数据栅格空间范围越大,检验点落在该栅格上的几率也就越大,模型精度也会越高.但是不应该为了追求模型的高准确性而损失细节,较大尺度的模型结果在区域范围内几乎没有指导物种人工种植和规划保护区的价值. ...
Maxent modeling for predicting the potential distribution of medicinal plant, Justicia adhatodaL. in Lesser Himalayan foothills
1
2013
... (2)环境因子带来的不确定性.环境因子的共线性.研究表明目前物种分布模型常用的环境因子数据,如Worldclim数据[64]的部分环境因子存在较强的共线性,会造成建模时统计信息的冗余,同时也会对建模的结果产生不利的影响[65,66].在环境数据准备时采用主成分分析(Principal Component Analysis,PCA)、相关系数(r)或者方差膨胀因子(Variance Inflation Factor,VIF)来对环境因子进行降维处理,可以有效地解决这一问题[4,67].环境因子的空间分辨率.环境因子的空间分辨率决定了物种分布模型结果的空间分辨率,不同尺度的研究应使用不同大小的空间分辨率,对于全球范围内的研究,可以使用较小分辨率的数据(2.5~10 min)[68],但是在区域尺度上应该使用较大分辨率的数据(30 s甚至更细分辨率的数据)[69].一般而言数据栅格空间范围越大,检验点落在该栅格上的几率也就越大,模型精度也会越高.但是不应该为了追求模型的高准确性而损失细节,较大尺度的模型结果在区域范围内几乎没有指导物种人工种植和规划保护区的价值. ...
Range shifts in response to climate change of, Ophiocordyceps sinensis, a fungus endemic to the Tibetan Plateau
2
2017
... (2)环境因子带来的不确定性.环境因子的共线性.研究表明目前物种分布模型常用的环境因子数据,如Worldclim数据[64]的部分环境因子存在较强的共线性,会造成建模时统计信息的冗余,同时也会对建模的结果产生不利的影响[65,66].在环境数据准备时采用主成分分析(Principal Component Analysis,PCA)、相关系数(r)或者方差膨胀因子(Variance Inflation Factor,VIF)来对环境因子进行降维处理,可以有效地解决这一问题[4,67].环境因子的空间分辨率.环境因子的空间分辨率决定了物种分布模型结果的空间分辨率,不同尺度的研究应使用不同大小的空间分辨率,对于全球范围内的研究,可以使用较小分辨率的数据(2.5~10 min)[68],但是在区域尺度上应该使用较大分辨率的数据(30 s甚至更细分辨率的数据)[69].一般而言数据栅格空间范围越大,检验点落在该栅格上的几率也就越大,模型精度也会越高.但是不应该为了追求模型的高准确性而损失细节,较大尺度的模型结果在区域范围内几乎没有指导物种人工种植和规划保护区的价值. ...
... 国内的物种分布模型研究主要集中在对具体物种的潜在分布预测上,尤其是中文期刊文章,其主要研究对象为中草药[27,66]、经济作物[82]、荒漠物种[69,83]、濒危物种[11]以及外来入侵物种[68]等,研究目标主要集中于物种潜在适宜生境分布预测,气候变化背景下物种分布区的迁移以及灭绝风险,生物多样性评估,入侵风险评估等方面,主要研究方法是MAXENT等简单易用的模型软件(图3).其中中草药适宜生境以及其质量分布格局研究是我国物种分布研究的特色之一,研究者使用模糊数学方法,成功实现了在有限数据支持下,药材质量空间格局的预测与其对气候变化响应的相关研究[27,42,43]. ...
Paintings predict the distribution of species, or the challenge of selecting environmental predictors and evaluation statistics
1
2018
... (2)环境因子带来的不确定性.环境因子的共线性.研究表明目前物种分布模型常用的环境因子数据,如Worldclim数据[64]的部分环境因子存在较强的共线性,会造成建模时统计信息的冗余,同时也会对建模的结果产生不利的影响[65,66].在环境数据准备时采用主成分分析(Principal Component Analysis,PCA)、相关系数(r)或者方差膨胀因子(Variance Inflation Factor,VIF)来对环境因子进行降维处理,可以有效地解决这一问题[4,67].环境因子的空间分辨率.环境因子的空间分辨率决定了物种分布模型结果的空间分辨率,不同尺度的研究应使用不同大小的空间分辨率,对于全球范围内的研究,可以使用较小分辨率的数据(2.5~10 min)[68],但是在区域尺度上应该使用较大分辨率的数据(30 s甚至更细分辨率的数据)[69].一般而言数据栅格空间范围越大,检验点落在该栅格上的几率也就越大,模型精度也会越高.但是不应该为了追求模型的高准确性而损失细节,较大尺度的模型结果在区域范围内几乎没有指导物种人工种植和规划保护区的价值. ...
Impacts of the spatial scale of climate data on the modeled distribution probabilities of invasive tree species throughout the world
2
2016
... (2)环境因子带来的不确定性.环境因子的共线性.研究表明目前物种分布模型常用的环境因子数据,如Worldclim数据[64]的部分环境因子存在较强的共线性,会造成建模时统计信息的冗余,同时也会对建模的结果产生不利的影响[65,66].在环境数据准备时采用主成分分析(Principal Component Analysis,PCA)、相关系数(r)或者方差膨胀因子(Variance Inflation Factor,VIF)来对环境因子进行降维处理,可以有效地解决这一问题[4,67].环境因子的空间分辨率.环境因子的空间分辨率决定了物种分布模型结果的空间分辨率,不同尺度的研究应使用不同大小的空间分辨率,对于全球范围内的研究,可以使用较小分辨率的数据(2.5~10 min)[68],但是在区域尺度上应该使用较大分辨率的数据(30 s甚至更细分辨率的数据)[69].一般而言数据栅格空间范围越大,检验点落在该栅格上的几率也就越大,模型精度也会越高.但是不应该为了追求模型的高准确性而损失细节,较大尺度的模型结果在区域范围内几乎没有指导物种人工种植和规划保护区的价值. ...
... 国内的物种分布模型研究主要集中在对具体物种的潜在分布预测上,尤其是中文期刊文章,其主要研究对象为中草药[27,66]、经济作物[82]、荒漠物种[69,83]、濒危物种[11]以及外来入侵物种[68]等,研究目标主要集中于物种潜在适宜生境分布预测,气候变化背景下物种分布区的迁移以及灭绝风险,生物多样性评估,入侵风险评估等方面,主要研究方法是MAXENT等简单易用的模型软件(图3).其中中草药适宜生境以及其质量分布格局研究是我国物种分布研究的特色之一,研究者使用模糊数学方法,成功实现了在有限数据支持下,药材质量空间格局的预测与其对气候变化响应的相关研究[27,42,43]. ...
Modeling the distribution of Populus euphratica in the Heihe River Basin, an inland river basin in an arid region of China
5
2018
... (2)环境因子带来的不确定性.环境因子的共线性.研究表明目前物种分布模型常用的环境因子数据,如Worldclim数据[64]的部分环境因子存在较强的共线性,会造成建模时统计信息的冗余,同时也会对建模的结果产生不利的影响[65,66].在环境数据准备时采用主成分分析(Principal Component Analysis,PCA)、相关系数(r)或者方差膨胀因子(Variance Inflation Factor,VIF)来对环境因子进行降维处理,可以有效地解决这一问题[4,67].环境因子的空间分辨率.环境因子的空间分辨率决定了物种分布模型结果的空间分辨率,不同尺度的研究应使用不同大小的空间分辨率,对于全球范围内的研究,可以使用较小分辨率的数据(2.5~10 min)[68],但是在区域尺度上应该使用较大分辨率的数据(30 s甚至更细分辨率的数据)[69].一般而言数据栅格空间范围越大,检验点落在该栅格上的几率也就越大,模型精度也会越高.但是不应该为了追求模型的高准确性而损失细节,较大尺度的模型结果在区域范围内几乎没有指导物种人工种植和规划保护区的价值. ...
... 目前已有大量的物种分布模型研究致力于濒危物种[81]、经济物种(中草药、果树、园林植物和农作物)[82]以及环境指示性物种的保护研究[69,83],也有部分研究致力于关键区域典型群落以及生态系统的保护[84,85],但是大部分此类研究都是停留在理论层面,只有极少部分文章报道了物种分布模型支撑下的物种保护实践.如何有效地服务于社会实践是物种分布模型面临的最大挑战,也是模型未来发展的现实需求.Guisan等[80]2013年提出了将物种分布模型融入到物种保护决策支持系统的理论框架(图2),在此框架内物种分布模型的潜在应用有:识别问题,如预测气候变化对目标物种适宜生境的影响或者确定外来入侵物种潜在的危害区域,预测人类活动对目标物种扩散造成的影响,识别关键区域,保护受到威胁的物种;提出可执行方案,主要是指利用物种分布模型评估识别物种灭绝以及生物入侵的热点区域,以划定保护区范围以及制定保护措施;模拟不同方案的管理效果,例如根据不同保护区划定后的土地利用变化等动态数据过滤物种分布模型结果,以确定方案的可行性;不确定性评价,决策过程中的不确定性不可消除,物种分布模型可以量化环境适宜性空间预测中的某些类型的不确定性,如估算保护不足和过度保护的可能后果以及成本差异[80]. ...
... 此外具体的物种保护或者生态系统管理工作一般都是区域尺度,需要十分精细的物种分布信息以及更加准确的区域基础信息.针对此种现状,在面向实践应用的相关研究中,较高分辨率且能够表现区域生境特征的环境变量更加适用,同时采用野外采样等方法获取更加精确的物种发生点位数据,也是保证模型在区域尺度精确性的主要手段之一[34,69],而在静态模型中结合土地利用变化等动态数据过滤物种分布模型结果,可以使物种分布模型的结果更加贴近实际,更加有指向性的为物种保护工作提出决策建议. ...
... 目前随着技术的进步,具有空间属性的地球科学领域大数据已经成为推动地学、生物地理学和生态学等相关学科发展的主要助力之一[100].地学大数据可以提供更为丰富且精确的环境信息及物种分布信息,但是如何有效的整合不同分辨率不同时相的海量地学数据是物种分布模型的挑战之一.目前已有研究尝试将遥感数据作为模型输入补充建模数据.遥感数据补充采样点数据.遥感数据能够获得野外调查难以完全涵盖的大的斑块和景观尺度上的物种分布点位数据[101],同时在环境恶劣的区域,高精度遥感数据可作为物种分布点位数据的来源之一[69,102].遥感数据作为环境变量数据.目前基于海量的遥感数据,我们获得了具生态意义的遥感产品,如蒸散(Evaportranspiration,ET)、叶面积指数(Leaf Area Index,LAI)、植被归一化指数(Normalized Difference Vegetation Index,NDVI)和植被覆盖度等数据,这些数据能够在一定程度上提高物种分布模型的精度[101].通过NDVI和LAI我们还可以计算区域植被物候数据,包括生长季节的开始日期和长度、最大绿度的持续日期以及常用的NDVI的平均值、最大值和变化幅度等.已有研究证实此类数据对于某些特殊生境(如荒漠)物种分布具有重要意义[101~104],同时植被结构、生产力和物候等在一定程度上可能与温度和降水一样影响着某些物种的生境质量.遥感数据也可以用来提高现有气候数据的精度和覆盖度,Vega等[105]综合了28个卫星数据产品生成再分析数据,采用与WorldClim(基于气象站点)相同的计算和插值方法生成了基于卫星数据的19个Bioclimatic变量.与WorldClim数据相比,该数据覆盖范围更广,包括南极地区,同时该数据也提高了Bio变量在没有气象站点区域的数据精度. ...
... 国内的物种分布模型研究主要集中在对具体物种的潜在分布预测上,尤其是中文期刊文章,其主要研究对象为中草药[27,66]、经济作物[82]、荒漠物种[69,83]、濒危物种[11]以及外来入侵物种[68]等,研究目标主要集中于物种潜在适宜生境分布预测,气候变化背景下物种分布区的迁移以及灭绝风险,生物多样性评估,入侵风险评估等方面,主要研究方法是MAXENT等简单易用的模型软件(图3).其中中草药适宜生境以及其质量分布格局研究是我国物种分布研究的特色之一,研究者使用模糊数学方法,成功实现了在有限数据支持下,药材质量空间格局的预测与其对气候变化响应的相关研究[27,42,43]. ...
Incorporating uncertainty in predictive species distribution modelling
1
2012
... (3)模型算法的不确定性.物种分布模型中模型的选择和参数的设定都会带来建模结果的不确定性[39,49,70],因此根据建模目标的生理生态特征与建模数据的特征,选择合适的统计算法以及参数化方案显得尤为重要. ...
Using species distribution modeling to assess factors that determine the distribution of two parapatric howlers (Alouatta spp.) in South America
1
2014
... 物种分布模型不仅适用于生态学基础性研究,也适用于应用性研究.如识别物种分布的主要影响因素[71],测试生物地理假说[72],评估生态位保守性[73],评估生物入侵风险[8],或评估全球变化对物种分布和多样性的影响等[74,75].同时此类模型也越来越多地应用于同物种不同特征表现的研究,如功能性状、次生类群或基因,在此基础上,与其他学科的工具和数据耦合,能够为谱系生物地理学、系统发育学、群体遗传学、种群动态等方面的研究提供便利[4,74,76].但是在具体实践研究时面临着以下挑战. ...
Hypothesis-driven species distribution models for tree species in the Bavarian Alps
1
2011
... 物种分布模型不仅适用于生态学基础性研究,也适用于应用性研究.如识别物种分布的主要影响因素[71],测试生物地理假说[72],评估生态位保守性[73],评估生物入侵风险[8],或评估全球变化对物种分布和多样性的影响等[74,75].同时此类模型也越来越多地应用于同物种不同特征表现的研究,如功能性状、次生类群或基因,在此基础上,与其他学科的工具和数据耦合,能够为谱系生物地理学、系统发育学、群体遗传学、种群动态等方面的研究提供便利[4,74,76].但是在具体实践研究时面临着以下挑战. ...
Within-taxon niche structure: Niche conservatism, divergence and predicted effects of climate change
2
2011
... 物种分布模型不仅适用于生态学基础性研究,也适用于应用性研究.如识别物种分布的主要影响因素[71],测试生物地理假说[72],评估生态位保守性[73],评估生物入侵风险[8],或评估全球变化对物种分布和多样性的影响等[74,75].同时此类模型也越来越多地应用于同物种不同特征表现的研究,如功能性状、次生类群或基因,在此基础上,与其他学科的工具和数据耦合,能够为谱系生物地理学、系统发育学、群体遗传学、种群动态等方面的研究提供便利[4,74,76].但是在具体实践研究时面临着以下挑战. ...
... 生态位演化分析是生态学和进化生物学的一个活跃研究领域[90].评估生态位保守性的一种方法是在系统发育树上分析环境约束,并探讨何种程度的环境关联性可以被认作局域适应.这种想法的实现要求在物种分布模型研究中将研究目标定义为种群而不是物种,也就是说,在亚物种水平上研究环境驱动力的生态位反应.Pearman等[73]的研究证实了亚种群生境范围与所属物种的生境范围并不一致.该研究表明在一定条件下,利用物种数据进行亚物种分布区的研究将会造成模型结果的不确定性.更重要的是,他们发现在亚种群模型中产生的环境响应曲线的形状不同于物种层次.物种生态位的保守性与演化是目前物种分布模型成功预测的关键,特别是物种分布区时空外推的研究.因此未来的研究应该更好地理解物种生态位的范围、生态位演化的影响以及对环境限制的适应机制. ...
The impact of global climate change on genetic diversity within populations and species
3
2013
... 物种分布模型不仅适用于生态学基础性研究,也适用于应用性研究.如识别物种分布的主要影响因素[71],测试生物地理假说[72],评估生态位保守性[73],评估生物入侵风险[8],或评估全球变化对物种分布和多样性的影响等[74,75].同时此类模型也越来越多地应用于同物种不同特征表现的研究,如功能性状、次生类群或基因,在此基础上,与其他学科的工具和数据耦合,能够为谱系生物地理学、系统发育学、群体遗传学、种群动态等方面的研究提供便利[4,74,76].但是在具体实践研究时面临着以下挑战. ...
... ,74,76].但是在具体实践研究时面临着以下挑战. ...
... 谱系生物地理学主要研究基因谱系(尤其是种内和近缘种间)地理格局的历史演化以及形成的原理和过程[91].谱系生物地理学方法在以下方面具有优势:识别生物地理屏障和避难所;测试和选择种群数量统计学模型;检验生态位的时间保守性[75,91].景观遗传学将群体遗传学、景观生态学和空间统计学相结合,研究环境异质性对遗传变异空间分布的影响.它可以用来量化景观组成、布局和特征对遗传连接性的影响,识别基因流和物种迁移廊道的障碍[92,93].景观遗传学在以下方面具有优势:集合种群的景观生态学连通性和源/汇动态定量研究;识别景观中的适应性变化.将谱系生物地理学及景观遗传学原理纳入物种分布模型框架的出口是物种分子标记数据,不同采样点分子标记提供了物种分布模型建模的基本数据,同时遗传和分子信息可以进一步揭示物种的历史动态以及现在的种群信息,这些信息有利于在统一的物种分布模型框架下有效地整合气候和种群动态等驱动因素[74,76].此外,在亚物种级别识别物种多样性并将这些信息纳入物种分布模型建模框架内,有利于管理者识别物种具有进化潜力的区域. ...
Integrating ensemble species distribution modelling and statistical phylogeography to inform projections of climate change impacts on species distributions
2
2013
... 物种分布模型不仅适用于生态学基础性研究,也适用于应用性研究.如识别物种分布的主要影响因素[71],测试生物地理假说[72],评估生态位保守性[73],评估生物入侵风险[8],或评估全球变化对物种分布和多样性的影响等[74,75].同时此类模型也越来越多地应用于同物种不同特征表现的研究,如功能性状、次生类群或基因,在此基础上,与其他学科的工具和数据耦合,能够为谱系生物地理学、系统发育学、群体遗传学、种群动态等方面的研究提供便利[4,74,76].但是在具体实践研究时面临着以下挑战. ...
... 谱系生物地理学主要研究基因谱系(尤其是种内和近缘种间)地理格局的历史演化以及形成的原理和过程[91].谱系生物地理学方法在以下方面具有优势:识别生物地理屏障和避难所;测试和选择种群数量统计学模型;检验生态位的时间保守性[75,91].景观遗传学将群体遗传学、景观生态学和空间统计学相结合,研究环境异质性对遗传变异空间分布的影响.它可以用来量化景观组成、布局和特征对遗传连接性的影响,识别基因流和物种迁移廊道的障碍[92,93].景观遗传学在以下方面具有优势:集合种群的景观生态学连通性和源/汇动态定量研究;识别景观中的适应性变化.将谱系生物地理学及景观遗传学原理纳入物种分布模型框架的出口是物种分子标记数据,不同采样点分子标记提供了物种分布模型建模的基本数据,同时遗传和分子信息可以进一步揭示物种的历史动态以及现在的种群信息,这些信息有利于在统一的物种分布模型框架下有效地整合气候和种群动态等驱动因素[74,76].此外,在亚物种级别识别物种多样性并将这些信息纳入物种分布模型建模框架内,有利于管理者识别物种具有进化潜力的区域. ...
A case for incorporating phylogeography and landscape genetics into species distribution modelling approaches to improve climate adaptation and conservation planning
2
2010
... 物种分布模型不仅适用于生态学基础性研究,也适用于应用性研究.如识别物种分布的主要影响因素[71],测试生物地理假说[72],评估生态位保守性[73],评估生物入侵风险[8],或评估全球变化对物种分布和多样性的影响等[74,75].同时此类模型也越来越多地应用于同物种不同特征表现的研究,如功能性状、次生类群或基因,在此基础上,与其他学科的工具和数据耦合,能够为谱系生物地理学、系统发育学、群体遗传学、种群动态等方面的研究提供便利[4,74,76].但是在具体实践研究时面临着以下挑战. ...
... 谱系生物地理学主要研究基因谱系(尤其是种内和近缘种间)地理格局的历史演化以及形成的原理和过程[91].谱系生物地理学方法在以下方面具有优势:识别生物地理屏障和避难所;测试和选择种群数量统计学模型;检验生态位的时间保守性[75,91].景观遗传学将群体遗传学、景观生态学和空间统计学相结合,研究环境异质性对遗传变异空间分布的影响.它可以用来量化景观组成、布局和特征对遗传连接性的影响,识别基因流和物种迁移廊道的障碍[92,93].景观遗传学在以下方面具有优势:集合种群的景观生态学连通性和源/汇动态定量研究;识别景观中的适应性变化.将谱系生物地理学及景观遗传学原理纳入物种分布模型框架的出口是物种分子标记数据,不同采样点分子标记提供了物种分布模型建模的基本数据,同时遗传和分子信息可以进一步揭示物种的历史动态以及现在的种群信息,这些信息有利于在统一的物种分布模型框架下有效地整合气候和种群动态等驱动因素[74,76].此外,在亚物种级别识别物种多样性并将这些信息纳入物种分布模型建模框架内,有利于管理者识别物种具有进化潜力的区域. ...
Niche shifts during the global invasion of the Asian tiger mosquito, Aedes albopictus Skuse (Culicidae), revealed by reciprocal distribution models
1
2010
... 这里的外推性是指模型在空间、时间以及尺度上的外推性[1,2].空间上的外推最为典型的是外来物种入侵风险分析的相关研究,在此过程中,研究者应该避免选择物种原生产地与目标区域差异显著的间接变量,重点考虑气候土壤等直接变量因子.同时也不应该考虑原生产地生物相互作用等外源性因素,需要注意的是在入侵过程中,物种在目标区域可能会产生适宜性的生态位漂移[77].时间上的外推最为典型的是同一区域内气候变化对目标物种潜在分布区的影响,此类研究不应该仅考虑气候因子(气温和降水),还应该考虑物种扩散能力,以及环境中其他限制因子(土壤和植被)等,尤其是对于某些环境限制较强的特殊生境物种.物种分布模型空间尺度的转换较难实现,通常,在不同空间尺度上,物种的生态位显示不同的特征,其环境阈值也不同,需要其他信息辅助[4,78],尤其是针对物种分布模型的降尺度研究中. ...
Accounting for multi-scale spatial autocorrelation improves performance of invasive Species Distribution Modelling (iSDM)
1
2015
... 这里的外推性是指模型在空间、时间以及尺度上的外推性[1,2].空间上的外推最为典型的是外来物种入侵风险分析的相关研究,在此过程中,研究者应该避免选择物种原生产地与目标区域差异显著的间接变量,重点考虑气候土壤等直接变量因子.同时也不应该考虑原生产地生物相互作用等外源性因素,需要注意的是在入侵过程中,物种在目标区域可能会产生适宜性的生态位漂移[77].时间上的外推最为典型的是同一区域内气候变化对目标物种潜在分布区的影响,此类研究不应该仅考虑气候因子(气温和降水),还应该考虑物种扩散能力,以及环境中其他限制因子(土壤和植被)等,尤其是对于某些环境限制较强的特殊生境物种.物种分布模型空间尺度的转换较难实现,通常,在不同空间尺度上,物种的生态位显示不同的特征,其环境阈值也不同,需要其他信息辅助[4,78],尤其是针对物种分布模型的降尺度研究中. ...
Predicting the impacts of climate change, soils and vegetation types on the geographic distribution of Polyporus umbellatus in China
1
2019
... 这里适当的建模策略并不仅仅指选择合适的建模统计算法,更重要的是模型算法的组合策略.在某些特定的研究背景下,单一建模框架无法实现建模目标,就需要更为复杂的组合模型,如某些特殊生境物种(真菌蘑菇和荒漠植物等)对于环境中某些非气候环境因子依赖性较强,这些因子主导了此类物种的局地分布格局,同时也限制了物种在气候适宜生境中的扩散.为了解决这一问题,Guo 等[11,79]提出了综合物种分布模型构建策略,首先分别以气候因子等环境变量构建分布趋势模型,以限制环境因子构建物种分布限制模型,然后综合考虑两个模型的结果组成组合物种分布模型作为最终的模型结果,研究结果表明,该策略更加适合于特殊生境物种分布以及对其气候变化响应的研究.当物种分布模型建模目标不仅仅是物种适宜生境分布还包含物种其他定量评价目标时(生物量、种群适宜性和植物药材质量等),可以显示的表达环境因子与建模目标的统计关系的回归模型(广义线性、广义相加和模糊物元等)具有一定优势.同时在此类研究中,带额外信息的采样点数据一般较少,导致模型模拟的物种生态位边界过大或者过小,可以通过补充一般物种分布点位数据(存在—缺失数据)构建物种适宜生境分布模型,以此结果划定定量评价模型的研究范围. ...
Predicting species distributions for conservation decisions
4
2013
... 目前已有大量的物种分布模型研究致力于濒危物种[81]、经济物种(中草药、果树、园林植物和农作物)[82]以及环境指示性物种的保护研究[69,83],也有部分研究致力于关键区域典型群落以及生态系统的保护[84,85],但是大部分此类研究都是停留在理论层面,只有极少部分文章报道了物种分布模型支撑下的物种保护实践.如何有效地服务于社会实践是物种分布模型面临的最大挑战,也是模型未来发展的现实需求.Guisan等[80]2013年提出了将物种分布模型融入到物种保护决策支持系统的理论框架(图2),在此框架内物种分布模型的潜在应用有:识别问题,如预测气候变化对目标物种适宜生境的影响或者确定外来入侵物种潜在的危害区域,预测人类活动对目标物种扩散造成的影响,识别关键区域,保护受到威胁的物种;提出可执行方案,主要是指利用物种分布模型评估识别物种灭绝以及生物入侵的热点区域,以划定保护区范围以及制定保护措施;模拟不同方案的管理效果,例如根据不同保护区划定后的土地利用变化等动态数据过滤物种分布模型结果,以确定方案的可行性;不确定性评价,决策过程中的不确定性不可消除,物种分布模型可以量化环境适宜性空间预测中的某些类型的不确定性,如估算保护不足和过度保护的可能后果以及成本差异[80]. ...
... [80]. ...
... 基于物种分布模型的物种保护决策过程(据参考文献[
80]修改)
<strong>Decision-making process for species conservation and management based on species distribution model </strong>(<strong>modified after reference </strong>[<xref ref-type="bibr" rid="R80">80</xref>])Fig.2![]()
此外具体的物种保护或者生态系统管理工作一般都是区域尺度,需要十分精细的物种分布信息以及更加准确的区域基础信息.针对此种现状,在面向实践应用的相关研究中,较高分辨率且能够表现区域生境特征的环境变量更加适用,同时采用野外采样等方法获取更加精确的物种发生点位数据,也是保证模型在区域尺度精确性的主要手段之一[34,69],而在静态模型中结合土地利用变化等动态数据过滤物种分布模型结果,可以使物种分布模型的结果更加贴近实际,更加有指向性的为物种保护工作提出决策建议. ...
... [
80])
Fig.2![]()
此外具体的物种保护或者生态系统管理工作一般都是区域尺度,需要十分精细的物种分布信息以及更加准确的区域基础信息.针对此种现状,在面向实践应用的相关研究中,较高分辨率且能够表现区域生境特征的环境变量更加适用,同时采用野外采样等方法获取更加精确的物种发生点位数据,也是保证模型在区域尺度精确性的主要手段之一[34,69],而在静态模型中结合土地利用变化等动态数据过滤物种分布模型结果,可以使物种分布模型的结果更加贴近实际,更加有指向性的为物种保护工作提出决策建议. ...
Landscape to site variations in species distribution models for endangered plants
1
2016
... 目前已有大量的物种分布模型研究致力于濒危物种[81]、经济物种(中草药、果树、园林植物和农作物)[82]以及环境指示性物种的保护研究[69,83],也有部分研究致力于关键区域典型群落以及生态系统的保护[84,85],但是大部分此类研究都是停留在理论层面,只有极少部分文章报道了物种分布模型支撑下的物种保护实践.如何有效地服务于社会实践是物种分布模型面临的最大挑战,也是模型未来发展的现实需求.Guisan等[80]2013年提出了将物种分布模型融入到物种保护决策支持系统的理论框架(图2),在此框架内物种分布模型的潜在应用有:识别问题,如预测气候变化对目标物种适宜生境的影响或者确定外来入侵物种潜在的危害区域,预测人类活动对目标物种扩散造成的影响,识别关键区域,保护受到威胁的物种;提出可执行方案,主要是指利用物种分布模型评估识别物种灭绝以及生物入侵的热点区域,以划定保护区范围以及制定保护措施;模拟不同方案的管理效果,例如根据不同保护区划定后的土地利用变化等动态数据过滤物种分布模型结果,以确定方案的可行性;不确定性评价,决策过程中的不确定性不可消除,物种分布模型可以量化环境适宜性空间预测中的某些类型的不确定性,如估算保护不足和过度保护的可能后果以及成本差异[80]. ...
中国植物分布模拟研究现状
2
2019
... 目前已有大量的物种分布模型研究致力于濒危物种[81]、经济物种(中草药、果树、园林植物和农作物)[82]以及环境指示性物种的保护研究[69,83],也有部分研究致力于关键区域典型群落以及生态系统的保护[84,85],但是大部分此类研究都是停留在理论层面,只有极少部分文章报道了物种分布模型支撑下的物种保护实践.如何有效地服务于社会实践是物种分布模型面临的最大挑战,也是模型未来发展的现实需求.Guisan等[80]2013年提出了将物种分布模型融入到物种保护决策支持系统的理论框架(图2),在此框架内物种分布模型的潜在应用有:识别问题,如预测气候变化对目标物种适宜生境的影响或者确定外来入侵物种潜在的危害区域,预测人类活动对目标物种扩散造成的影响,识别关键区域,保护受到威胁的物种;提出可执行方案,主要是指利用物种分布模型评估识别物种灭绝以及生物入侵的热点区域,以划定保护区范围以及制定保护措施;模拟不同方案的管理效果,例如根据不同保护区划定后的土地利用变化等动态数据过滤物种分布模型结果,以确定方案的可行性;不确定性评价,决策过程中的不确定性不可消除,物种分布模型可以量化环境适宜性空间预测中的某些类型的不确定性,如估算保护不足和过度保护的可能后果以及成本差异[80]. ...
... 国内的物种分布模型研究主要集中在对具体物种的潜在分布预测上,尤其是中文期刊文章,其主要研究对象为中草药[27,66]、经济作物[82]、荒漠物种[69,83]、濒危物种[11]以及外来入侵物种[68]等,研究目标主要集中于物种潜在适宜生境分布预测,气候变化背景下物种分布区的迁移以及灭绝风险,生物多样性评估,入侵风险评估等方面,主要研究方法是MAXENT等简单易用的模型软件(图3).其中中草药适宜生境以及其质量分布格局研究是我国物种分布研究的特色之一,研究者使用模糊数学方法,成功实现了在有限数据支持下,药材质量空间格局的预测与其对气候变化响应的相关研究[27,42,43]. ...
中国植物分布模拟研究现状
2
2019
... 目前已有大量的物种分布模型研究致力于濒危物种[81]、经济物种(中草药、果树、园林植物和农作物)[82]以及环境指示性物种的保护研究[69,83],也有部分研究致力于关键区域典型群落以及生态系统的保护[84,85],但是大部分此类研究都是停留在理论层面,只有极少部分文章报道了物种分布模型支撑下的物种保护实践.如何有效地服务于社会实践是物种分布模型面临的最大挑战,也是模型未来发展的现实需求.Guisan等[80]2013年提出了将物种分布模型融入到物种保护决策支持系统的理论框架(图2),在此框架内物种分布模型的潜在应用有:识别问题,如预测气候变化对目标物种适宜生境的影响或者确定外来入侵物种潜在的危害区域,预测人类活动对目标物种扩散造成的影响,识别关键区域,保护受到威胁的物种;提出可执行方案,主要是指利用物种分布模型评估识别物种灭绝以及生物入侵的热点区域,以划定保护区范围以及制定保护措施;模拟不同方案的管理效果,例如根据不同保护区划定后的土地利用变化等动态数据过滤物种分布模型结果,以确定方案的可行性;不确定性评价,决策过程中的不确定性不可消除,物种分布模型可以量化环境适宜性空间预测中的某些类型的不确定性,如估算保护不足和过度保护的可能后果以及成本差异[80]. ...
... 国内的物种分布模型研究主要集中在对具体物种的潜在分布预测上,尤其是中文期刊文章,其主要研究对象为中草药[27,66]、经济作物[82]、荒漠物种[69,83]、濒危物种[11]以及外来入侵物种[68]等,研究目标主要集中于物种潜在适宜生境分布预测,气候变化背景下物种分布区的迁移以及灭绝风险,生物多样性评估,入侵风险评估等方面,主要研究方法是MAXENT等简单易用的模型软件(图3).其中中草药适宜生境以及其质量分布格局研究是我国物种分布研究的特色之一,研究者使用模糊数学方法,成功实现了在有限数据支持下,药材质量空间格局的预测与其对气候变化响应的相关研究[27,42,43]. ...
The potential geographical distribution of Haloxylon across Central Asia under climate change in the 21st century
2
2019
... 目前已有大量的物种分布模型研究致力于濒危物种[81]、经济物种(中草药、果树、园林植物和农作物)[82]以及环境指示性物种的保护研究[69,83],也有部分研究致力于关键区域典型群落以及生态系统的保护[84,85],但是大部分此类研究都是停留在理论层面,只有极少部分文章报道了物种分布模型支撑下的物种保护实践.如何有效地服务于社会实践是物种分布模型面临的最大挑战,也是模型未来发展的现实需求.Guisan等[80]2013年提出了将物种分布模型融入到物种保护决策支持系统的理论框架(图2),在此框架内物种分布模型的潜在应用有:识别问题,如预测气候变化对目标物种适宜生境的影响或者确定外来入侵物种潜在的危害区域,预测人类活动对目标物种扩散造成的影响,识别关键区域,保护受到威胁的物种;提出可执行方案,主要是指利用物种分布模型评估识别物种灭绝以及生物入侵的热点区域,以划定保护区范围以及制定保护措施;模拟不同方案的管理效果,例如根据不同保护区划定后的土地利用变化等动态数据过滤物种分布模型结果,以确定方案的可行性;不确定性评价,决策过程中的不确定性不可消除,物种分布模型可以量化环境适宜性空间预测中的某些类型的不确定性,如估算保护不足和过度保护的可能后果以及成本差异[80]. ...
... 国内的物种分布模型研究主要集中在对具体物种的潜在分布预测上,尤其是中文期刊文章,其主要研究对象为中草药[27,66]、经济作物[82]、荒漠物种[69,83]、濒危物种[11]以及外来入侵物种[68]等,研究目标主要集中于物种潜在适宜生境分布预测,气候变化背景下物种分布区的迁移以及灭绝风险,生物多样性评估,入侵风险评估等方面,主要研究方法是MAXENT等简单易用的模型软件(图3).其中中草药适宜生境以及其质量分布格局研究是我国物种分布研究的特色之一,研究者使用模糊数学方法,成功实现了在有限数据支持下,药材质量空间格局的预测与其对气候变化响应的相关研究[27,42,43]. ...
SESAM—A new framework integrating macroecological and species distribution models for predicting spatio-temporal patterns of species assemblages
1
2011
... 目前已有大量的物种分布模型研究致力于濒危物种[81]、经济物种(中草药、果树、园林植物和农作物)[82]以及环境指示性物种的保护研究[69,83],也有部分研究致力于关键区域典型群落以及生态系统的保护[84,85],但是大部分此类研究都是停留在理论层面,只有极少部分文章报道了物种分布模型支撑下的物种保护实践.如何有效地服务于社会实践是物种分布模型面临的最大挑战,也是模型未来发展的现实需求.Guisan等[80]2013年提出了将物种分布模型融入到物种保护决策支持系统的理论框架(图2),在此框架内物种分布模型的潜在应用有:识别问题,如预测气候变化对目标物种适宜生境的影响或者确定外来入侵物种潜在的危害区域,预测人类活动对目标物种扩散造成的影响,识别关键区域,保护受到威胁的物种;提出可执行方案,主要是指利用物种分布模型评估识别物种灭绝以及生物入侵的热点区域,以划定保护区范围以及制定保护措施;模拟不同方案的管理效果,例如根据不同保护区划定后的土地利用变化等动态数据过滤物种分布模型结果,以确定方案的可行性;不确定性评价,决策过程中的不确定性不可消除,物种分布模型可以量化环境适宜性空间预测中的某些类型的不确定性,如估算保护不足和过度保护的可能后果以及成本差异[80]. ...
Predicting climate change effects on wetland ecosystem services using species distribution modeling and plant functional traits
1
2015
... 目前已有大量的物种分布模型研究致力于濒危物种[81]、经济物种(中草药、果树、园林植物和农作物)[82]以及环境指示性物种的保护研究[69,83],也有部分研究致力于关键区域典型群落以及生态系统的保护[84,85],但是大部分此类研究都是停留在理论层面,只有极少部分文章报道了物种分布模型支撑下的物种保护实践.如何有效地服务于社会实践是物种分布模型面临的最大挑战,也是模型未来发展的现实需求.Guisan等[80]2013年提出了将物种分布模型融入到物种保护决策支持系统的理论框架(图2),在此框架内物种分布模型的潜在应用有:识别问题,如预测气候变化对目标物种适宜生境的影响或者确定外来入侵物种潜在的危害区域,预测人类活动对目标物种扩散造成的影响,识别关键区域,保护受到威胁的物种;提出可执行方案,主要是指利用物种分布模型评估识别物种灭绝以及生物入侵的热点区域,以划定保护区范围以及制定保护措施;模拟不同方案的管理效果,例如根据不同保护区划定后的土地利用变化等动态数据过滤物种分布模型结果,以确定方案的可行性;不确定性评价,决策过程中的不确定性不可消除,物种分布模型可以量化环境适宜性空间预测中的某些类型的不确定性,如估算保护不足和过度保护的可能后果以及成本差异[80]. ...
New trends in species distribution modelling
1
2010
... 物种分布建模的一个前提是处于平衡状态的物种生态需求,所以在建模时一般不考虑历史因素对分布范围以及分布格局的影响.这种平衡假设是一种理想状态,很可能造成物种分布建模结果的偏差[86].2014年Patsiou等[87]利用集合物种分布模型与高分辨率古气候和地形数据集重建了珍稀物种Saxifraga florulenta从末次盛冰期以来到现在的潜在分布,证明了地形与古气候对该物种当前乃至未来的分布具有影响.2015年Svenning等[88]阐述了历史因素如何影响物种丰富度的空间分布,也列举了有关第四纪冰期—间冰期气候变化对当前物种分布模式影响的充分证据,同时也表明历史气候因素对生物系统发育和功能多样性影响显著.2017年Fordham等[89]报道了由大气大洋耦合环流模式(Atmosphere‐Ocean General Circulation Model, AOGCM)生成精细的时间尺度(十年到百年)的过去2100年的气候模拟数据,该数据可以为解释过去气候条件对当今物种分布和生物多样性的影响提供数据基础.随着气候环境数据的获取难度逐渐降低,精确古气候环境下物种分布的格局建模研究将成为可能,这将进一步加深研究者对形成当前物种分布格局、物种多样性的地理格局以及生态系统功能多样性的认识,同时有助于改进气候变化对物种分布以及区域物种多样性影响的研究. ...
Topo-climatic microrefugia explain the persistence of a rare endemic plant in the Alps during the last 21 millennia
1
2014
... 物种分布建模的一个前提是处于平衡状态的物种生态需求,所以在建模时一般不考虑历史因素对分布范围以及分布格局的影响.这种平衡假设是一种理想状态,很可能造成物种分布建模结果的偏差[86].2014年Patsiou等[87]利用集合物种分布模型与高分辨率古气候和地形数据集重建了珍稀物种Saxifraga florulenta从末次盛冰期以来到现在的潜在分布,证明了地形与古气候对该物种当前乃至未来的分布具有影响.2015年Svenning等[88]阐述了历史因素如何影响物种丰富度的空间分布,也列举了有关第四纪冰期—间冰期气候变化对当前物种分布模式影响的充分证据,同时也表明历史气候因素对生物系统发育和功能多样性影响显著.2017年Fordham等[89]报道了由大气大洋耦合环流模式(Atmosphere‐Ocean General Circulation Model, AOGCM)生成精细的时间尺度(十年到百年)的过去2100年的气候模拟数据,该数据可以为解释过去气候条件对当今物种分布和生物多样性的影响提供数据基础.随着气候环境数据的获取难度逐渐降低,精确古气候环境下物种分布的格局建模研究将成为可能,这将进一步加深研究者对形成当前物种分布格局、物种多样性的地理格局以及生态系统功能多样性的认识,同时有助于改进气候变化对物种分布以及区域物种多样性影响的研究. ...
The influence of paleoclimate on present-day patterns in biodiversity and ecosystems
1
2015
... 物种分布建模的一个前提是处于平衡状态的物种生态需求,所以在建模时一般不考虑历史因素对分布范围以及分布格局的影响.这种平衡假设是一种理想状态,很可能造成物种分布建模结果的偏差[86].2014年Patsiou等[87]利用集合物种分布模型与高分辨率古气候和地形数据集重建了珍稀物种Saxifraga florulenta从末次盛冰期以来到现在的潜在分布,证明了地形与古气候对该物种当前乃至未来的分布具有影响.2015年Svenning等[88]阐述了历史因素如何影响物种丰富度的空间分布,也列举了有关第四纪冰期—间冰期气候变化对当前物种分布模式影响的充分证据,同时也表明历史气候因素对生物系统发育和功能多样性影响显著.2017年Fordham等[89]报道了由大气大洋耦合环流模式(Atmosphere‐Ocean General Circulation Model, AOGCM)生成精细的时间尺度(十年到百年)的过去2100年的气候模拟数据,该数据可以为解释过去气候条件对当今物种分布和生物多样性的影响提供数据基础.随着气候环境数据的获取难度逐渐降低,精确古气候环境下物种分布的格局建模研究将成为可能,这将进一步加深研究者对形成当前物种分布格局、物种多样性的地理格局以及生态系统功能多样性的认识,同时有助于改进气候变化对物种分布以及区域物种多样性影响的研究. ...
Why decadal to century timescale paleoclimate data is needed to explain present-day patterns of biological diversity and change
1
2018
... 物种分布建模的一个前提是处于平衡状态的物种生态需求,所以在建模时一般不考虑历史因素对分布范围以及分布格局的影响.这种平衡假设是一种理想状态,很可能造成物种分布建模结果的偏差[86].2014年Patsiou等[87]利用集合物种分布模型与高分辨率古气候和地形数据集重建了珍稀物种Saxifraga florulenta从末次盛冰期以来到现在的潜在分布,证明了地形与古气候对该物种当前乃至未来的分布具有影响.2015年Svenning等[88]阐述了历史因素如何影响物种丰富度的空间分布,也列举了有关第四纪冰期—间冰期气候变化对当前物种分布模式影响的充分证据,同时也表明历史气候因素对生物系统发育和功能多样性影响显著.2017年Fordham等[89]报道了由大气大洋耦合环流模式(Atmosphere‐Ocean General Circulation Model, AOGCM)生成精细的时间尺度(十年到百年)的过去2100年的气候模拟数据,该数据可以为解释过去气候条件对当今物种分布和生物多样性的影响提供数据基础.随着气候环境数据的获取难度逐渐降低,精确古气候环境下物种分布的格局建模研究将成为可能,这将进一步加深研究者对形成当前物种分布格局、物种多样性的地理格局以及生态系统功能多样性的认识,同时有助于改进气候变化对物种分布以及区域物种多样性影响的研究. ...
Assessing effects of forecasted climate change on the diversity and distribution of European higher plants for 2050
1
2002
... 生态位演化分析是生态学和进化生物学的一个活跃研究领域[90].评估生态位保守性的一种方法是在系统发育树上分析环境约束,并探讨何种程度的环境关联性可以被认作局域适应.这种想法的实现要求在物种分布模型研究中将研究目标定义为种群而不是物种,也就是说,在亚物种水平上研究环境驱动力的生态位反应.Pearman等[73]的研究证实了亚种群生境范围与所属物种的生境范围并不一致.该研究表明在一定条件下,利用物种数据进行亚物种分布区的研究将会造成模型结果的不确定性.更重要的是,他们发现在亚种群模型中产生的环境响应曲线的形状不同于物种层次.物种生态位的保守性与演化是目前物种分布模型成功预测的关键,特别是物种分布区时空外推的研究.因此未来的研究应该更好地理解物种生态位的范围、生态位演化的影响以及对环境限制的适应机制. ...
Phylogeography-the history and formation of species
2
2000
... 谱系生物地理学主要研究基因谱系(尤其是种内和近缘种间)地理格局的历史演化以及形成的原理和过程[91].谱系生物地理学方法在以下方面具有优势:识别生物地理屏障和避难所;测试和选择种群数量统计学模型;检验生态位的时间保守性[75,91].景观遗传学将群体遗传学、景观生态学和空间统计学相结合,研究环境异质性对遗传变异空间分布的影响.它可以用来量化景观组成、布局和特征对遗传连接性的影响,识别基因流和物种迁移廊道的障碍[92,93].景观遗传学在以下方面具有优势:集合种群的景观生态学连通性和源/汇动态定量研究;识别景观中的适应性变化.将谱系生物地理学及景观遗传学原理纳入物种分布模型框架的出口是物种分子标记数据,不同采样点分子标记提供了物种分布模型建模的基本数据,同时遗传和分子信息可以进一步揭示物种的历史动态以及现在的种群信息,这些信息有利于在统一的物种分布模型框架下有效地整合气候和种群动态等驱动因素[74,76].此外,在亚物种级别识别物种多样性并将这些信息纳入物种分布模型建模框架内,有利于管理者识别物种具有进化潜力的区域. ...
... ,91].景观遗传学将群体遗传学、景观生态学和空间统计学相结合,研究环境异质性对遗传变异空间分布的影响.它可以用来量化景观组成、布局和特征对遗传连接性的影响,识别基因流和物种迁移廊道的障碍[92,93].景观遗传学在以下方面具有优势:集合种群的景观生态学连通性和源/汇动态定量研究;识别景观中的适应性变化.将谱系生物地理学及景观遗传学原理纳入物种分布模型框架的出口是物种分子标记数据,不同采样点分子标记提供了物种分布模型建模的基本数据,同时遗传和分子信息可以进一步揭示物种的历史动态以及现在的种群信息,这些信息有利于在统一的物种分布模型框架下有效地整合气候和种群动态等驱动因素[74,76].此外,在亚物种级别识别物种多样性并将这些信息纳入物种分布模型建模框架内,有利于管理者识别物种具有进化潜力的区域. ...
Beyond species distribution modeling: A landscape genetics approach to investigating range shifts under future climate change
1
2015
... 谱系生物地理学主要研究基因谱系(尤其是种内和近缘种间)地理格局的历史演化以及形成的原理和过程[91].谱系生物地理学方法在以下方面具有优势:识别生物地理屏障和避难所;测试和选择种群数量统计学模型;检验生态位的时间保守性[75,91].景观遗传学将群体遗传学、景观生态学和空间统计学相结合,研究环境异质性对遗传变异空间分布的影响.它可以用来量化景观组成、布局和特征对遗传连接性的影响,识别基因流和物种迁移廊道的障碍[92,93].景观遗传学在以下方面具有优势:集合种群的景观生态学连通性和源/汇动态定量研究;识别景观中的适应性变化.将谱系生物地理学及景观遗传学原理纳入物种分布模型框架的出口是物种分子标记数据,不同采样点分子标记提供了物种分布模型建模的基本数据,同时遗传和分子信息可以进一步揭示物种的历史动态以及现在的种群信息,这些信息有利于在统一的物种分布模型框架下有效地整合气候和种群动态等驱动因素[74,76].此外,在亚物种级别识别物种多样性并将这些信息纳入物种分布模型建模框架内,有利于管理者识别物种具有进化潜力的区域. ...
Putting the "landscape" in landscape genetics
1
2007
... 谱系生物地理学主要研究基因谱系(尤其是种内和近缘种间)地理格局的历史演化以及形成的原理和过程[91].谱系生物地理学方法在以下方面具有优势:识别生物地理屏障和避难所;测试和选择种群数量统计学模型;检验生态位的时间保守性[75,91].景观遗传学将群体遗传学、景观生态学和空间统计学相结合,研究环境异质性对遗传变异空间分布的影响.它可以用来量化景观组成、布局和特征对遗传连接性的影响,识别基因流和物种迁移廊道的障碍[92,93].景观遗传学在以下方面具有优势:集合种群的景观生态学连通性和源/汇动态定量研究;识别景观中的适应性变化.将谱系生物地理学及景观遗传学原理纳入物种分布模型框架的出口是物种分子标记数据,不同采样点分子标记提供了物种分布模型建模的基本数据,同时遗传和分子信息可以进一步揭示物种的历史动态以及现在的种群信息,这些信息有利于在统一的物种分布模型框架下有效地整合气候和种群动态等驱动因素[74,76].此外,在亚物种级别识别物种多样性并将这些信息纳入物种分布模型建模框架内,有利于管理者识别物种具有进化潜力的区域. ...
When and how should biotic interactions be considered in models of species niches and distributions
1
2017
... 目前,大多数物种分布模型在建模时不考虑生物相互作用,或者只在小尺度上考虑生物相互作用过程,因此模型通常只采用非生物的环境因子进行建模[3,4,6,94].然而已有研究证明将生物相互作用加入到模型中可以更好地模拟物种分布格局以及其对环境变化的响应[95,96].生物交互作用一般以如下方式集成到物种分布模型中:栅格单元内其他物种出现数据[96];目标物种所占比例数据[97];竞争系数[98];埃尔顿噪声假说(Eltonian noise hypothesis)[99]等.从理论上看,物种对于大的气候条件梯度的响应反映了哈钦森(Hutchinson)的多维超体积生态位.因此,物种分布模式在不同尺度下受到非生物预测因子和生物相互作用变量的影响,生物相互作用的重要性因尺度和位置而异[97].综上所述,未来物种分布模型研究应该将生物相互作用纳入模型框架内,同时在此过程中要着重考虑尺度效应对生物相互作用的影响. ...
Biotic and abiotic variables show little redundancy in explaining tree species distributions
1
2010
... 目前,大多数物种分布模型在建模时不考虑生物相互作用,或者只在小尺度上考虑生物相互作用过程,因此模型通常只采用非生物的环境因子进行建模[3,4,6,94].然而已有研究证明将生物相互作用加入到模型中可以更好地模拟物种分布格局以及其对环境变化的响应[95,96].生物交互作用一般以如下方式集成到物种分布模型中:栅格单元内其他物种出现数据[96];目标物种所占比例数据[97];竞争系数[98];埃尔顿噪声假说(Eltonian noise hypothesis)[99]等.从理论上看,物种对于大的气候条件梯度的响应反映了哈钦森(Hutchinson)的多维超体积生态位.因此,物种分布模式在不同尺度下受到非生物预测因子和生物相互作用变量的影响,生物相互作用的重要性因尺度和位置而异[97].综上所述,未来物种分布模型研究应该将生物相互作用纳入模型框架内,同时在此过程中要着重考虑尺度效应对生物相互作用的影响. ...
Biotic interactions improve prediction of boreal bird distributions at macro-scales
2
2010
... 目前,大多数物种分布模型在建模时不考虑生物相互作用,或者只在小尺度上考虑生物相互作用过程,因此模型通常只采用非生物的环境因子进行建模[3,4,6,94].然而已有研究证明将生物相互作用加入到模型中可以更好地模拟物种分布格局以及其对环境变化的响应[95,96].生物交互作用一般以如下方式集成到物种分布模型中:栅格单元内其他物种出现数据[96];目标物种所占比例数据[97];竞争系数[98];埃尔顿噪声假说(Eltonian noise hypothesis)[99]等.从理论上看,物种对于大的气候条件梯度的响应反映了哈钦森(Hutchinson)的多维超体积生态位.因此,物种分布模式在不同尺度下受到非生物预测因子和生物相互作用变量的影响,生物相互作用的重要性因尺度和位置而异[97].综上所述,未来物种分布模型研究应该将生物相互作用纳入模型框架内,同时在此过程中要着重考虑尺度效应对生物相互作用的影响. ...
... [96];目标物种所占比例数据[97];竞争系数[98];埃尔顿噪声假说(Eltonian noise hypothesis)[99]等.从理论上看,物种对于大的气候条件梯度的响应反映了哈钦森(Hutchinson)的多维超体积生态位.因此,物种分布模式在不同尺度下受到非生物预测因子和生物相互作用变量的影响,生物相互作用的重要性因尺度和位置而异[97].综上所述,未来物种分布模型研究应该将生物相互作用纳入模型框架内,同时在此过程中要着重考虑尺度效应对生物相互作用的影响. ...
Co-occurrence patterns of trees along macro-climatic gradients and their potential influence on the present and future distribution of Fagus sylvaticaL
2
2011
... 目前,大多数物种分布模型在建模时不考虑生物相互作用,或者只在小尺度上考虑生物相互作用过程,因此模型通常只采用非生物的环境因子进行建模[3,4,6,94].然而已有研究证明将生物相互作用加入到模型中可以更好地模拟物种分布格局以及其对环境变化的响应[95,96].生物交互作用一般以如下方式集成到物种分布模型中:栅格单元内其他物种出现数据[96];目标物种所占比例数据[97];竞争系数[98];埃尔顿噪声假说(Eltonian noise hypothesis)[99]等.从理论上看,物种对于大的气候条件梯度的响应反映了哈钦森(Hutchinson)的多维超体积生态位.因此,物种分布模式在不同尺度下受到非生物预测因子和生物相互作用变量的影响,生物相互作用的重要性因尺度和位置而异[97].综上所述,未来物种分布模型研究应该将生物相互作用纳入模型框架内,同时在此过程中要着重考虑尺度效应对生物相互作用的影响. ...
... [97].综上所述,未来物种分布模型研究应该将生物相互作用纳入模型框架内,同时在此过程中要着重考虑尺度效应对生物相互作用的影响. ...
Assessing the potential impact of invasive ring‐necked parakeets Psittacula krameri on native nuthatches Sitta europeae in Belgium
1
2010
... 目前,大多数物种分布模型在建模时不考虑生物相互作用,或者只在小尺度上考虑生物相互作用过程,因此模型通常只采用非生物的环境因子进行建模[3,4,6,94].然而已有研究证明将生物相互作用加入到模型中可以更好地模拟物种分布格局以及其对环境变化的响应[95,96].生物交互作用一般以如下方式集成到物种分布模型中:栅格单元内其他物种出现数据[96];目标物种所占比例数据[97];竞争系数[98];埃尔顿噪声假说(Eltonian noise hypothesis)[99]等.从理论上看,物种对于大的气候条件梯度的响应反映了哈钦森(Hutchinson)的多维超体积生态位.因此,物种分布模式在不同尺度下受到非生物预测因子和生物相互作用变量的影响,生物相互作用的重要性因尺度和位置而异[97].综上所述,未来物种分布模型研究应该将生物相互作用纳入模型框架内,同时在此过程中要着重考虑尺度效应对生物相互作用的影响. ...
The importance of biotic interactions in species distribution models: A test of Eltonian noise hypothesis using parrots
1
2014
... 目前,大多数物种分布模型在建模时不考虑生物相互作用,或者只在小尺度上考虑生物相互作用过程,因此模型通常只采用非生物的环境因子进行建模[3,4,6,94].然而已有研究证明将生物相互作用加入到模型中可以更好地模拟物种分布格局以及其对环境变化的响应[95,96].生物交互作用一般以如下方式集成到物种分布模型中:栅格单元内其他物种出现数据[96];目标物种所占比例数据[97];竞争系数[98];埃尔顿噪声假说(Eltonian noise hypothesis)[99]等.从理论上看,物种对于大的气候条件梯度的响应反映了哈钦森(Hutchinson)的多维超体积生态位.因此,物种分布模式在不同尺度下受到非生物预测因子和生物相互作用变量的影响,生物相互作用的重要性因尺度和位置而异[97].综上所述,未来物种分布模型研究应该将生物相互作用纳入模型框架内,同时在此过程中要着重考虑尺度效应对生物相互作用的影响. ...
Big Earth data: A new frontier in Earth and information sciences
1
2017
... 目前随着技术的进步,具有空间属性的地球科学领域大数据已经成为推动地学、生物地理学和生态学等相关学科发展的主要助力之一[100].地学大数据可以提供更为丰富且精确的环境信息及物种分布信息,但是如何有效的整合不同分辨率不同时相的海量地学数据是物种分布模型的挑战之一.目前已有研究尝试将遥感数据作为模型输入补充建模数据.遥感数据补充采样点数据.遥感数据能够获得野外调查难以完全涵盖的大的斑块和景观尺度上的物种分布点位数据[101],同时在环境恶劣的区域,高精度遥感数据可作为物种分布点位数据的来源之一[69,102].遥感数据作为环境变量数据.目前基于海量的遥感数据,我们获得了具生态意义的遥感产品,如蒸散(Evaportranspiration,ET)、叶面积指数(Leaf Area Index,LAI)、植被归一化指数(Normalized Difference Vegetation Index,NDVI)和植被覆盖度等数据,这些数据能够在一定程度上提高物种分布模型的精度[101].通过NDVI和LAI我们还可以计算区域植被物候数据,包括生长季节的开始日期和长度、最大绿度的持续日期以及常用的NDVI的平均值、最大值和变化幅度等.已有研究证实此类数据对于某些特殊生境(如荒漠)物种分布具有重要意义[101~104],同时植被结构、生产力和物候等在一定程度上可能与温度和降水一样影响着某些物种的生境质量.遥感数据也可以用来提高现有气候数据的精度和覆盖度,Vega等[105]综合了28个卫星数据产品生成再分析数据,采用与WorldClim(基于气象站点)相同的计算和插值方法生成了基于卫星数据的19个Bioclimatic变量.与WorldClim数据相比,该数据覆盖范围更广,包括南极地区,同时该数据也提高了Bio变量在没有气象站点区域的数据精度. ...
Can remote sensing of land cover improve species distribution modelling
3
2010
... 目前随着技术的进步,具有空间属性的地球科学领域大数据已经成为推动地学、生物地理学和生态学等相关学科发展的主要助力之一[100].地学大数据可以提供更为丰富且精确的环境信息及物种分布信息,但是如何有效的整合不同分辨率不同时相的海量地学数据是物种分布模型的挑战之一.目前已有研究尝试将遥感数据作为模型输入补充建模数据.遥感数据补充采样点数据.遥感数据能够获得野外调查难以完全涵盖的大的斑块和景观尺度上的物种分布点位数据[101],同时在环境恶劣的区域,高精度遥感数据可作为物种分布点位数据的来源之一[69,102].遥感数据作为环境变量数据.目前基于海量的遥感数据,我们获得了具生态意义的遥感产品,如蒸散(Evaportranspiration,ET)、叶面积指数(Leaf Area Index,LAI)、植被归一化指数(Normalized Difference Vegetation Index,NDVI)和植被覆盖度等数据,这些数据能够在一定程度上提高物种分布模型的精度[101].通过NDVI和LAI我们还可以计算区域植被物候数据,包括生长季节的开始日期和长度、最大绿度的持续日期以及常用的NDVI的平均值、最大值和变化幅度等.已有研究证实此类数据对于某些特殊生境(如荒漠)物种分布具有重要意义[101~104],同时植被结构、生产力和物候等在一定程度上可能与温度和降水一样影响着某些物种的生境质量.遥感数据也可以用来提高现有气候数据的精度和覆盖度,Vega等[105]综合了28个卫星数据产品生成再分析数据,采用与WorldClim(基于气象站点)相同的计算和插值方法生成了基于卫星数据的19个Bioclimatic变量.与WorldClim数据相比,该数据覆盖范围更广,包括南极地区,同时该数据也提高了Bio变量在没有气象站点区域的数据精度. ...
... [101].通过NDVI和LAI我们还可以计算区域植被物候数据,包括生长季节的开始日期和长度、最大绿度的持续日期以及常用的NDVI的平均值、最大值和变化幅度等.已有研究证实此类数据对于某些特殊生境(如荒漠)物种分布具有重要意义[101~104],同时植被结构、生产力和物候等在一定程度上可能与温度和降水一样影响着某些物种的生境质量.遥感数据也可以用来提高现有气候数据的精度和覆盖度,Vega等[105]综合了28个卫星数据产品生成再分析数据,采用与WorldClim(基于气象站点)相同的计算和插值方法生成了基于卫星数据的19个Bioclimatic变量.与WorldClim数据相比,该数据覆盖范围更广,包括南极地区,同时该数据也提高了Bio变量在没有气象站点区域的数据精度. ...
... [101~104],同时植被结构、生产力和物候等在一定程度上可能与温度和降水一样影响着某些物种的生境质量.遥感数据也可以用来提高现有气候数据的精度和覆盖度,Vega等[105]综合了28个卫星数据产品生成再分析数据,采用与WorldClim(基于气象站点)相同的计算和插值方法生成了基于卫星数据的19个Bioclimatic变量.与WorldClim数据相比,该数据覆盖范围更广,包括南极地区,同时该数据也提高了Bio变量在没有气象站点区域的数据精度. ...
Remote sensing of structural complexity indices for habitat and species distribution modeling
1
2010
... 目前随着技术的进步,具有空间属性的地球科学领域大数据已经成为推动地学、生物地理学和生态学等相关学科发展的主要助力之一[100].地学大数据可以提供更为丰富且精确的环境信息及物种分布信息,但是如何有效的整合不同分辨率不同时相的海量地学数据是物种分布模型的挑战之一.目前已有研究尝试将遥感数据作为模型输入补充建模数据.遥感数据补充采样点数据.遥感数据能够获得野外调查难以完全涵盖的大的斑块和景观尺度上的物种分布点位数据[101],同时在环境恶劣的区域,高精度遥感数据可作为物种分布点位数据的来源之一[69,102].遥感数据作为环境变量数据.目前基于海量的遥感数据,我们获得了具生态意义的遥感产品,如蒸散(Evaportranspiration,ET)、叶面积指数(Leaf Area Index,LAI)、植被归一化指数(Normalized Difference Vegetation Index,NDVI)和植被覆盖度等数据,这些数据能够在一定程度上提高物种分布模型的精度[101].通过NDVI和LAI我们还可以计算区域植被物候数据,包括生长季节的开始日期和长度、最大绿度的持续日期以及常用的NDVI的平均值、最大值和变化幅度等.已有研究证实此类数据对于某些特殊生境(如荒漠)物种分布具有重要意义[101~104],同时植被结构、生产力和物候等在一定程度上可能与温度和降水一样影响着某些物种的生境质量.遥感数据也可以用来提高现有气候数据的精度和覆盖度,Vega等[105]综合了28个卫星数据产品生成再分析数据,采用与WorldClim(基于气象站点)相同的计算和插值方法生成了基于卫星数据的19个Bioclimatic变量.与WorldClim数据相比,该数据覆盖范围更广,包括南极地区,同时该数据也提高了Bio变量在没有气象站点区域的数据精度. ...
Remote sensing time series for modeling invasive species distribution: A case study of Tamarix spp. in the US and Mexico
2010
Combining ensemble modeling and remote sensing for mapping individual: Tree species at high spatial resolution
1
2013
... 目前随着技术的进步,具有空间属性的地球科学领域大数据已经成为推动地学、生物地理学和生态学等相关学科发展的主要助力之一[100].地学大数据可以提供更为丰富且精确的环境信息及物种分布信息,但是如何有效的整合不同分辨率不同时相的海量地学数据是物种分布模型的挑战之一.目前已有研究尝试将遥感数据作为模型输入补充建模数据.遥感数据补充采样点数据.遥感数据能够获得野外调查难以完全涵盖的大的斑块和景观尺度上的物种分布点位数据[101],同时在环境恶劣的区域,高精度遥感数据可作为物种分布点位数据的来源之一[69,102].遥感数据作为环境变量数据.目前基于海量的遥感数据,我们获得了具生态意义的遥感产品,如蒸散(Evaportranspiration,ET)、叶面积指数(Leaf Area Index,LAI)、植被归一化指数(Normalized Difference Vegetation Index,NDVI)和植被覆盖度等数据,这些数据能够在一定程度上提高物种分布模型的精度[101].通过NDVI和LAI我们还可以计算区域植被物候数据,包括生长季节的开始日期和长度、最大绿度的持续日期以及常用的NDVI的平均值、最大值和变化幅度等.已有研究证实此类数据对于某些特殊生境(如荒漠)物种分布具有重要意义[101~104],同时植被结构、生产力和物候等在一定程度上可能与温度和降水一样影响着某些物种的生境质量.遥感数据也可以用来提高现有气候数据的精度和覆盖度,Vega等[105]综合了28个卫星数据产品生成再分析数据,采用与WorldClim(基于气象站点)相同的计算和插值方法生成了基于卫星数据的19个Bioclimatic变量.与WorldClim数据相比,该数据覆盖范围更广,包括南极地区,同时该数据也提高了Bio变量在没有气象站点区域的数据精度. ...
Pertierra L R, Olalla-Tárraga M á. MERRAclim, a high-resolution global dataset of remotely sensed bioclimatic variables for ecological modelling
1
2017
... 目前随着技术的进步,具有空间属性的地球科学领域大数据已经成为推动地学、生物地理学和生态学等相关学科发展的主要助力之一[100].地学大数据可以提供更为丰富且精确的环境信息及物种分布信息,但是如何有效的整合不同分辨率不同时相的海量地学数据是物种分布模型的挑战之一.目前已有研究尝试将遥感数据作为模型输入补充建模数据.遥感数据补充采样点数据.遥感数据能够获得野外调查难以完全涵盖的大的斑块和景观尺度上的物种分布点位数据[101],同时在环境恶劣的区域,高精度遥感数据可作为物种分布点位数据的来源之一[69,102].遥感数据作为环境变量数据.目前基于海量的遥感数据,我们获得了具生态意义的遥感产品,如蒸散(Evaportranspiration,ET)、叶面积指数(Leaf Area Index,LAI)、植被归一化指数(Normalized Difference Vegetation Index,NDVI)和植被覆盖度等数据,这些数据能够在一定程度上提高物种分布模型的精度[101].通过NDVI和LAI我们还可以计算区域植被物候数据,包括生长季节的开始日期和长度、最大绿度的持续日期以及常用的NDVI的平均值、最大值和变化幅度等.已有研究证实此类数据对于某些特殊生境(如荒漠)物种分布具有重要意义[101~104],同时植被结构、生产力和物候等在一定程度上可能与温度和降水一样影响着某些物种的生境质量.遥感数据也可以用来提高现有气候数据的精度和覆盖度,Vega等[105]综合了28个卫星数据产品生成再分析数据,采用与WorldClim(基于气象站点)相同的计算和插值方法生成了基于卫星数据的19个Bioclimatic变量.与WorldClim数据相比,该数据覆盖范围更广,包括南极地区,同时该数据也提高了Bio变量在没有气象站点区域的数据精度. ...
Marble algorithm: A solution to estimating ecological niches from presence-only records
1
2015
... 尽管物种分布模型在我国起步较晚,但经过相关领域研究学者的努力,近10年取得了迅速发展.综合中英文文献的调查结果,文章发表数目已经和国外同行无显著差别.在模型算法方面,我国学者首次将支持向量机[32]和DBSCAN[106]算法引入到物种分布模型,并提出了利用相关物种共同建模[107]和利用主成分分析进行多模型整合[108]等方法以提高模型整体准确率;出现了ModEco[109]、mMWeb[110]、NicheA[111]和SDMvspecies[112]等一系列的建模工具;另外,上文中提到的模型选择[54,113,114],参数设置[59],变量选择[115],模型的外推能力[116]等与模型构建和性能相关的研究领域,均有我国相关研究学者的成果发表. ...
Using data from related species to overcome spatial sampling bias and associated limitations in ecological niche modelling
1
2017
... 尽管物种分布模型在我国起步较晚,但经过相关领域研究学者的努力,近10年取得了迅速发展.综合中英文文献的调查结果,文章发表数目已经和国外同行无显著差别.在模型算法方面,我国学者首次将支持向量机[32]和DBSCAN[106]算法引入到物种分布模型,并提出了利用相关物种共同建模[107]和利用主成分分析进行多模型整合[108]等方法以提高模型整体准确率;出现了ModEco[109]、mMWeb[110]、NicheA[111]和SDMvspecies[112]等一系列的建模工具;另外,上文中提到的模型选择[54,113,114],参数设置[59],变量选择[115],模型的外推能力[116]等与模型构建和性能相关的研究领域,均有我国相关研究学者的成果发表. ...
Do consensus models outperform individual models?Transferability evaluations of diverse modeling approaches for an invasive moth
1
2017
... 尽管物种分布模型在我国起步较晚,但经过相关领域研究学者的努力,近10年取得了迅速发展.综合中英文文献的调查结果,文章发表数目已经和国外同行无显著差别.在模型算法方面,我国学者首次将支持向量机[32]和DBSCAN[106]算法引入到物种分布模型,并提出了利用相关物种共同建模[107]和利用主成分分析进行多模型整合[108]等方法以提高模型整体准确率;出现了ModEco[109]、mMWeb[110]、NicheA[111]和SDMvspecies[112]等一系列的建模工具;另外,上文中提到的模型选择[54,113,114],参数设置[59],变量选择[115],模型的外推能力[116]等与模型构建和性能相关的研究领域,均有我国相关研究学者的成果发表. ...
ModEco: An integrated software package for ecological niche modeling
1
2010
... 尽管物种分布模型在我国起步较晚,但经过相关领域研究学者的努力,近10年取得了迅速发展.综合中英文文献的调查结果,文章发表数目已经和国外同行无显著差别.在模型算法方面,我国学者首次将支持向量机[32]和DBSCAN[106]算法引入到物种分布模型,并提出了利用相关物种共同建模[107]和利用主成分分析进行多模型整合[108]等方法以提高模型整体准确率;出现了ModEco[109]、mMWeb[110]、NicheA[111]和SDMvspecies[112]等一系列的建模工具;另外,上文中提到的模型选择[54,113,114],参数设置[59],变量选择[115],模型的外推能力[116]等与模型构建和性能相关的研究领域,均有我国相关研究学者的成果发表. ...
mMWeb—An online platform for employing multiple ecological niche modeling algorithms
1
2012
... 尽管物种分布模型在我国起步较晚,但经过相关领域研究学者的努力,近10年取得了迅速发展.综合中英文文献的调查结果,文章发表数目已经和国外同行无显著差别.在模型算法方面,我国学者首次将支持向量机[32]和DBSCAN[106]算法引入到物种分布模型,并提出了利用相关物种共同建模[107]和利用主成分分析进行多模型整合[108]等方法以提高模型整体准确率;出现了ModEco[109]、mMWeb[110]、NicheA[111]和SDMvspecies[112]等一系列的建模工具;另外,上文中提到的模型选择[54,113,114],参数设置[59],变量选择[115],模型的外推能力[116]等与模型构建和性能相关的研究领域,均有我国相关研究学者的成果发表. ...
NicheA: Creating virtual species and ecological niches in multivariate environmental scenarios
1
2016
... 尽管物种分布模型在我国起步较晚,但经过相关领域研究学者的努力,近10年取得了迅速发展.综合中英文文献的调查结果,文章发表数目已经和国外同行无显著差别.在模型算法方面,我国学者首次将支持向量机[32]和DBSCAN[106]算法引入到物种分布模型,并提出了利用相关物种共同建模[107]和利用主成分分析进行多模型整合[108]等方法以提高模型整体准确率;出现了ModEco[109]、mMWeb[110]、NicheA[111]和SDMvspecies[112]等一系列的建模工具;另外,上文中提到的模型选择[54,113,114],参数设置[59],变量选择[115],模型的外推能力[116]等与模型构建和性能相关的研究领域,均有我国相关研究学者的成果发表. ...
Sdmvspecies: A software for creating virtual species for species distribution modelling
1
2015
... 尽管物种分布模型在我国起步较晚,但经过相关领域研究学者的努力,近10年取得了迅速发展.综合中英文文献的调查结果,文章发表数目已经和国外同行无显著差别.在模型算法方面,我国学者首次将支持向量机[32]和DBSCAN[106]算法引入到物种分布模型,并提出了利用相关物种共同建模[107]和利用主成分分析进行多模型整合[108]等方法以提高模型整体准确率;出现了ModEco[109]、mMWeb[110]、NicheA[111]和SDMvspecies[112]等一系列的建模工具;另外,上文中提到的模型选择[54,113,114],参数设置[59],变量选择[115],模型的外推能力[116]等与模型构建和性能相关的研究领域,均有我国相关研究学者的成果发表. ...
A checklist for maximizing reproducibility of ecological niche models
1
2019
... 尽管物种分布模型在我国起步较晚,但经过相关领域研究学者的努力,近10年取得了迅速发展.综合中英文文献的调查结果,文章发表数目已经和国外同行无显著差别.在模型算法方面,我国学者首次将支持向量机[32]和DBSCAN[106]算法引入到物种分布模型,并提出了利用相关物种共同建模[107]和利用主成分分析进行多模型整合[108]等方法以提高模型整体准确率;出现了ModEco[109]、mMWeb[110]、NicheA[111]和SDMvspecies[112]等一系列的建模工具;另外,上文中提到的模型选择[54,113,114],参数设置[59],变量选择[115],模型的外推能力[116]等与模型构建和性能相关的研究领域,均有我国相关研究学者的成果发表. ...
The effect of sample size on the accuracy of species distribution models: Considering both presences and pseudo-absences or background sites
1
2019
... 尽管物种分布模型在我国起步较晚,但经过相关领域研究学者的努力,近10年取得了迅速发展.综合中英文文献的调查结果,文章发表数目已经和国外同行无显著差别.在模型算法方面,我国学者首次将支持向量机[32]和DBSCAN[106]算法引入到物种分布模型,并提出了利用相关物种共同建模[107]和利用主成分分析进行多模型整合[108]等方法以提高模型整体准确率;出现了ModEco[109]、mMWeb[110]、NicheA[111]和SDMvspecies[112]等一系列的建模工具;另外,上文中提到的模型选择[54,113,114],参数设置[59],变量选择[115],模型的外推能力[116]等与模型构建和性能相关的研究领域,均有我国相关研究学者的成果发表. ...
Detecting outliers in species distribution data
1
2018
... 尽管物种分布模型在我国起步较晚,但经过相关领域研究学者的努力,近10年取得了迅速发展.综合中英文文献的调查结果,文章发表数目已经和国外同行无显著差别.在模型算法方面,我国学者首次将支持向量机[32]和DBSCAN[106]算法引入到物种分布模型,并提出了利用相关物种共同建模[107]和利用主成分分析进行多模型整合[108]等方法以提高模型整体准确率;出现了ModEco[109]、mMWeb[110]、NicheA[111]和SDMvspecies[112]等一系列的建模工具;另外,上文中提到的模型选择[54,113,114],参数设置[59],变量选择[115],模型的外推能力[116]等与模型构建和性能相关的研究领域,均有我国相关研究学者的成果发表. ...
An evaluation of transferability of ecological niche models
1
2019
... 尽管物种分布模型在我国起步较晚,但经过相关领域研究学者的努力,近10年取得了迅速发展.综合中英文文献的调查结果,文章发表数目已经和国外同行无显著差别.在模型算法方面,我国学者首次将支持向量机[32]和DBSCAN[106]算法引入到物种分布模型,并提出了利用相关物种共同建模[107]和利用主成分分析进行多模型整合[108]等方法以提高模型整体准确率;出现了ModEco[109]、mMWeb[110]、NicheA[111]和SDMvspecies[112]等一系列的建模工具;另外,上文中提到的模型选择[54,113,114],参数设置[59],变量选择[115],模型的外推能力[116]等与模型构建和性能相关的研究领域,均有我国相关研究学者的成果发表. ...




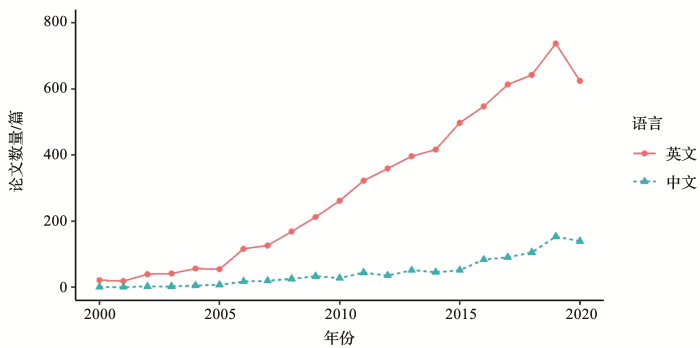
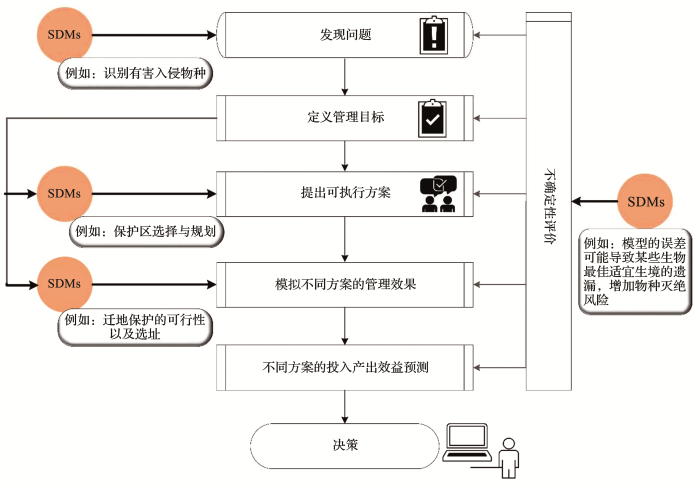


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}