
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于支持向量机的川中杂卤石分类识别研究
[陈科贵1  , 吴刘磊
, 吴刘磊1*, * , 陈愿愿2 , 王刚3 ]
, 吴刘磊, 陈愿愿|
|


作者简介:陈科贵(1959-),男,四川自贡人,教授,主要从事石油地质、测井储层评价技术和四川钾盐普查研究.E-mail:chenkegui@21cn.com
杂卤石是四川盆地主要的固态钾矿物,川中地区大多数杂卤石层不纯,通常伴随石膏层、硬石膏层、盐岩层发育,甚至同层沉积,常规测井解释方法只能粗略地识别杂卤石层。以支持向量机理论和测井解释为基础,测井数据作为输入,构建预测模型,对川中地区下中三叠统杂卤石样本做精细识别,将识别结果与录井资料验证对比,正确率达到90%以上。再以预测模型为基础,结合含杂卤石岩性在测井曲线上的响应情况,构建杂卤石层分类识别模型,识别杂卤石层、石膏质杂卤石层和杂卤石膏岩层,识别正确率达到91.78%,与常规测井解释方法相比具有明显优势。结果表明,将支持向量机运用到找钾矿中具有广阔的前景。
First author:Chen Kegui(1959-), male, Zigong City, Sichuan Province,Professor.Research areas include petroleum geology, technology of well logging reservoir evaluation and survey research potash in Sichuan.E-mail:chenkegui@21cn.com
*Corresponding author:Wu Liulei(1992-),male, Rugao City,Jiangsu Province, Master student. Research areas include logging interpretation.E-mail:1556883301@qq.com
Polyhalite is mainly solid mineral potassium in Sichuan Basin, The most of polyhalite layer in Sichuan region is impurity, and usually accompanied by layers of gypsum, anhydrite, rock salt, and even deposited in the same layer. Conventional logging interpretation method can only roughly identificate polyhalite layers. Based on the theory of Support Vector Machine and logging interpretation methods,this paper creates prediction model with the input of logging curves, and discriminates the polyhalite reservoirs in the lower-middle Triassic strata. Compared with logging data, the accuracy rate of the discrimination results reaches 90%. According to the prediction model, identification model can be established with the curve features of polyhalite to discriminate pure polyhalite reservoirs, gypsiferous polyhalite reservoirs and polyhalite-gypsum reservoirs, the accuracy rate is 91.78%. The study demonstrates that Support Vector Machine is superior to the method of logging interpretation, and it has broad prospects in potash exploration.
杂卤石[K2MgCa2(SO4)4· 2H2O]为含钾复盐矿物, 钾盐矿床的发现一般都是从含钾线索开始, 例如在石油、石盐矿的勘探中发现含钾指示, 从而做进一步的工作。在钻井过程中可溶性钾盐易溶解, 杂卤石却属于难溶含钾矿物, 因此杂卤石岩的发现可以作为钾盐资源的指示[1]。长期以来, 杂卤石层的测井识别主要靠放射性测井, 其他常规测井方法为辅。2014年, 陈科贵等[2]研究出用曲线重叠法和交会图法识别杂卤石。至于是否为纯杂卤石层则主要依靠测井曲线幅度值的高低来判断[3, 4], 这些方法识别精度都不高且识别速度较慢。研究区部分井的杂卤石并不纯, 多含石膏质, 有些为杂卤石膏岩, 这使得用测井曲线识别杂卤石类别、判断杂卤石含量非常困难。近年来, 越来越多的人将支持向量机方法运用到识别复杂岩性、结合测井曲线分层等方面[5, 6], 但在钾盐矿物识别领域还无人涉及, 因此, 利用该方法识别固体钾矿, 为寻找钾资源提供了新的思路。
本文在测井资料和录井资料的基础上, 充分利用杂卤石在测井曲线上的响应特征, 利用支持向量机方法来识别杂卤石, 然后进一步对杂卤石含量高低作出判断、划分类别, 最后用准确的录井分析结果和模型识别结果进行对比, 对模型的识别能力进行评价。运用支持向量机识别杂卤石这一方法拓展了
测井资料在杂卤石等含钾矿物识别中的运用, 并为后期运用测井资料找寻其他类别钾盐矿物提供了良好的参考。
川中地区位于四川盆地川西凹陷带中东部, 构造上为一次级凹陷[7]。川中三叠系沉积受苏皖运动及印支运动影响, 主要表现为海退[8], 在海退期沉积石膏、盐岩、杂卤石等蒸发岩类, 其中杂卤石在龙女寺构造地区和广安地区沉积情况较好。如表1所示, 龙女寺地区杂卤石沉积厚度为24 m, 但含石膏质较重, 录井显示大部分为杂卤石膏岩。广安地区杂卤石最厚沉积20 m且稍含石膏质, 部分地区夹薄层石膏或盐岩。
| 表1 川中地区杂卤石分布层位及厚度 Table 1 Polyhalite isopch map of in the middle of Sichuan Basin |
四川盆地的杂卤石主要沉积于石膏、硬石膏和盐岩之中, 测井响应特征为:自然伽马(GR)高值相对高值; 声波时差(AC)通常为55~95 μ s/ft; 电阻率(RLLD)和高补偿中子(CNL)相对高值; 密度(DEN)高值, 为2.72~2.78。在自然伽马能谱测井曲线上, 杂卤石的反映为高K, 低Th和U, 杂卤石层在自然伽马能谱测井曲线上的响应非常明显(图1)。但研究区地层岩性复杂, 杂卤石层与石膏互层, 夹杂石膏质杂卤石和杂卤石膏岩, 且黏土矿物类型及含量变化大, 给解释造成了困难。因此本文运用支持向量机方法来识别研究区的杂卤石层。
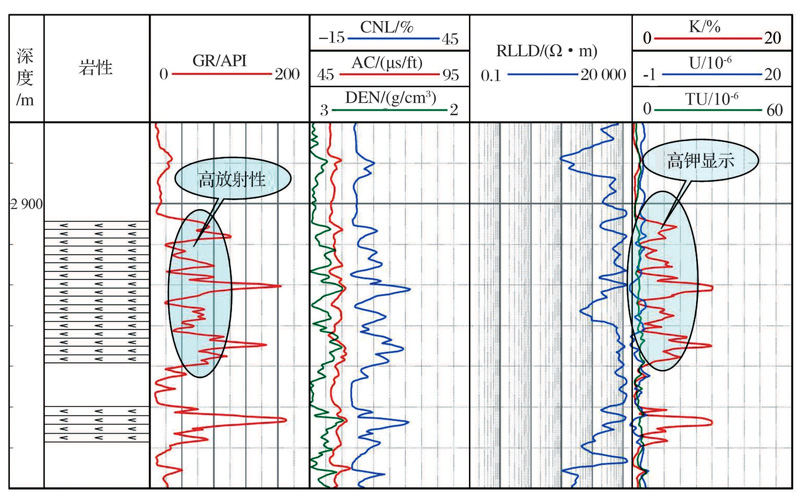 | 图1 杂卤石测井响应特征图Fig.1 Logging interpretaition of polyhalite |
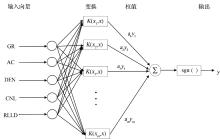
支持向量机(Support Vector Machine, SVM)具有通用性、鲁棒性、有效性、计算简单和理论完善等优点[9, 10], 其主要思想是建立一个决策曲面, 寻找一个平衡点最大地隔离正例和反例[11]。支持向量机的理论基础是统计学习理论, 以结构风险最小化为原则[12, 13]。其基本结构如图2所示。
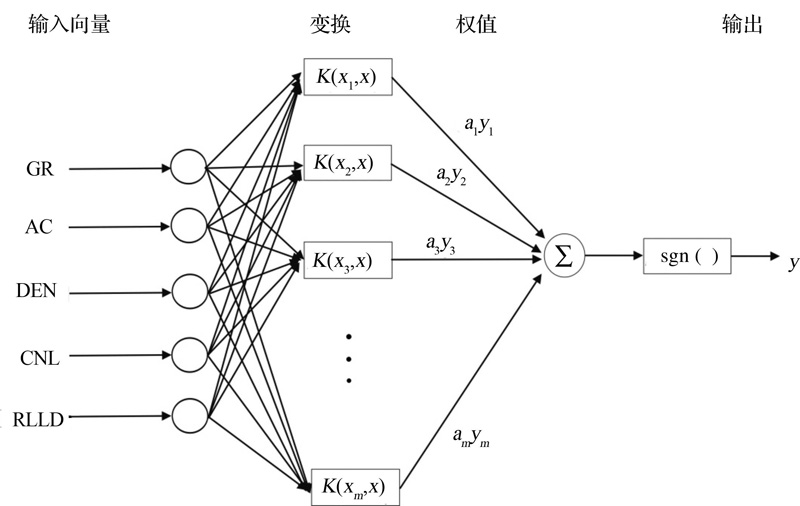 | 图2 支持向量机结构图Fig.2 The structure of SVM |
在学习样本确定后, 建立预测模型需要找到相应的支持向量机的参数:核函数(Kernel Function)和惩罚因子(C)[14]。最常用的核函数有以下3种[15]:
(1)多项式内积函数:
K(χ i, χ )=[(χ i· χ )+1]q (1)
(2)RBF核函数:
K(χ i, χ )=exp
(3)Sigmoid核函数:
K(χ i, χ )=tanh(υ (χ i· χ ))+c (3)
式中:q, σ , υ 和c为核参数。
对于以上3种核函数, 试验后测试集预测分类准确率的对比如表2所示。
| 表2 采用不同核函数对比 Table 2 Comparison of different kernel functions |
通过以上对比, 可以看出采用RBF核函数时最终的分类准确率最高。
在分析研究区岩心和测井参数对应的基础上, 确定能够较好地反映杂卤石的测井曲线。本文中, 选取自然伽马(GR)、中子密度(CNL)、声波(AC)、密度(DEN)、深侧向电阻率(RLLD)5条测井曲线作为输入特征。
所有的学习样本要进行归一化处理, 将每一组学习样本特征归一到[0, 1], 采用MATLAB中的mapminmax函数对数据进行归一化处理。
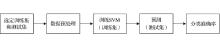
模型建立的第一步是选择学习样本和测试样本组成训练集和测试集, 然后对数据进行预处理, 对数据归一化之后对训练集进行训练, 最后用建立的模型对测试集进行预测, 确定分类标签[16]。算法流程如图3所示:
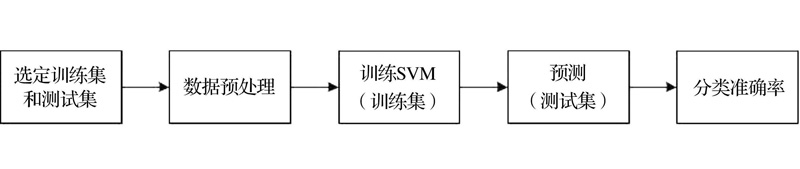 | 图3 模型整体流程Fig.3 The overall process of model |
在使用建立的模型将测试数据进行分类时, 需要先对惩罚参数C和核函数参数g进行寻优, 在这里并不知道C和g应该取多少, 因此要对(C, g)进行参数搜索。目标是使得寻找到的参数最优, 能够最准确地预测结果[17, 18]。
“ 交叉验证法” 是目前国际上使用较多且准确率较高的方法, 因此本文使用“ 交叉验证法” 进行参数寻优。首先使用“ 网格搜索” 让C和g在一定范围内取值, 把训练集作为原始数据集进行训练, 得到对应每组参数的验证分类准确率, 验证精确度最高的即是最优参数。当有多组参数都能够得到最高的验证分类准确率时, 为了避免当惩罚参数C过高时使分类模型产生学习状态, 导致训练集分类准确率很高而测试集分类准确率却很低(分类器的泛化能力降低)的情况发生, 直接选取参数C最小的一组[19]。
选取CV-cg算法, 经过多次调试后将C, g在3的指数范围网格里进行查找。经过上述方法得到最优参数(C, g)=(1, 2)。
以研究区内含杂卤石井的GR, AC, CNL, DEN和RLLD作为输入, 选取80个学习样本组成训练集进行SVM训练, 其中6个学习样本如表3所示。然后用选定的测试样本组成测试集进行训练, 最后将测试结果与做了归位后准确的录井分析结果对比。广3井杂卤石层对比情况如图4所示。
| 表3 学习样本示例 Table 3 Examples of study samples |
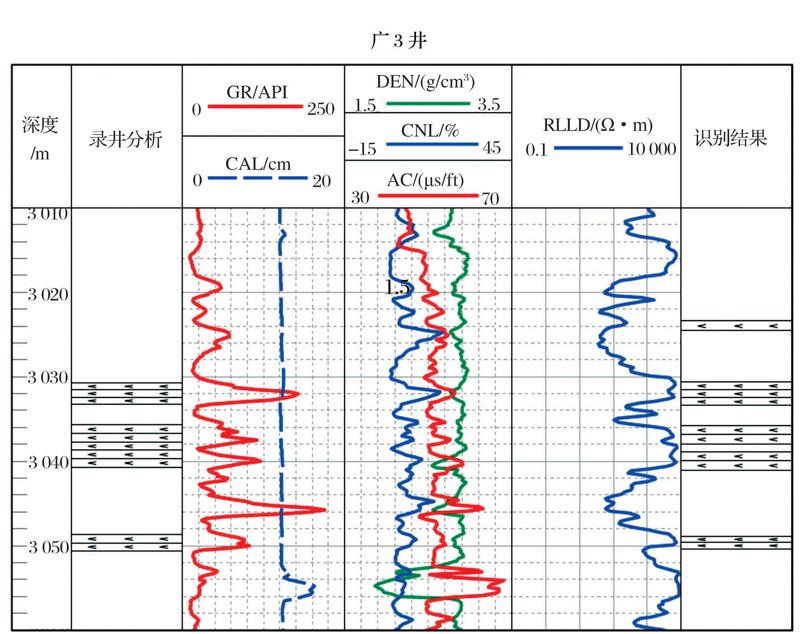 | 图4 广3井杂卤石层识别结果对比图Fig.4 Correlation of polyhalite discrimination in Guang 3 well |
对比结果表明:支持向量机识别结果与实际结果符合度较高, 另外, 在研究区内选择了另外4口井进行杂卤石层的识别, 统计识别结果, 得出各井的正确率如表4所示。
从上述4口井的测试结果来看, 这5条测井曲线作为输入, 正确率达到了90%以上, 可见支持向量机识别模型的识别能力较好。
| 表4 杂卤石层识别正确率表 Table 4 Accuracy of polyhalite discrimination |
在川中地区杂卤石通常与石膏、硬石膏、盐岩互层, 甚至同层沉积, 因此区内大多数杂卤石层不纯, 这些岩层由于杂卤石含量不同, 在测井响应特征上GR, AC, RLLD和CNL的曲线值会有一定的变化。但由于常规测井解释方法的局限性, 解释时无法把这些与纯杂卤石层有差异的层段区分开来, 只能全部解释为杂卤石层。本文以建立的支持向量机模型为基础, 增加了几种其他岩性识别参数, 对广参2井的含杂卤石层段进行测试, 并将结果与录井分析和测井解释的结果进行对比, 对比结果如表5所示, 识别正确率达到91.78%, 识别效果好。
| 表5 分类识别杂卤石层结果对比表 Table 5 Corralation of classification results of polyhalite |
(1) 以GR, AC, DEN, CNL, RLLD 5条测井曲线值作为输入, 构建预测模型识别杂卤石, 预测正确率可以达到90%以上, 识别效果显著。
(2) 支持向量机可以较为精确地划分出杂卤石层、杂卤石膏岩层和石膏质杂卤石层, 正确率达91.78%, 对复杂岩性的识别效果十分显著。
(3) 支持向量机为杂卤石的识别、杂卤石含量和复杂岩性的判断提供了一种新的手段, 且识别和划分效果显著, 与常规测井解释方法对比, 该方法识别速度快, 识别的准确率较高, 该方法简单易操作。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|